大模型推理优化系统性指南:从模型到部署,告别瞎优化,实现降本增效
这篇文章系统介绍了企业级大模型推理优化的四层次策略:基础模型层(量化、剪枝、蒸馏)、推理引擎层(KV缓存优化、动态批处理)、系统部署层(分布式推理、硬件选型)和数据应用层(Prompt工程)。作者强调大模型推理存在多维瓶颈,优化需系统诊断、全栈考量,避免盲目套用工具,才能真正实现降本增效。
这篇文章系统介绍了企业级大模型推理优化的四层次策略:基础模型层(量化、剪枝、蒸馏)、推理引擎层(KV缓存优化、动态批处理)、系统部署层(分布式推理、硬件选型)和数据应用层(Prompt工程)。作者强调大模型推理存在多维瓶颈,优化需系统诊断、全栈考量,避免盲目套用工具,才能真正实现降本增效。
前排提示,文末有大模型AGI-CSDN独家资料包哦!

线上部署了一个百亿参数的大模型,TPS上不去,延迟爆炸,老板天天问成本,团队里的小伙伴各自拿着TensorRT、vLLM甚至手改PyTorch Kernel,结果非但没好,反而出了更多问题,甚至还引入了模型精度下降、稳定性不足等新坑。这样的场景,是不是很熟悉?
企业级大模型推理优化,远不是简单地套用几个工具就能解决的。它是一个系统的工程问题,需要深入理解模型特性、硬件瓶颈、软件栈以及业务需求。那些“瞎优化”的尝试,往往因为缺乏整体观,最终陷入事倍功半的困境。
别再瞎优化了:大模型推理的系统性瓶颈
我们首先要搞清楚,大模型推理的瓶颈在哪里。它不是单一的,而是多维度的:
-
- 计算瓶颈 (Compute-bound):模型参数量巨大,导致FLOPs(浮点运算次数)极高,CPU/GPU的算力成为限制。这是最直观的瓶颈。
-
- 内存带宽瓶颈 (Memory Bandwidth-bound):大模型推理中,KV Cache、模型权重加载等都会产生大量的内存读写,尤其是在生成长序列时,KV Cache会迅速膨胀,HBM(高带宽内存)的带宽往往成为瓶颈。很多时候,GPU的算力并没有跑满,而是在等待数据传输。
-
- IO瓶颈 (I/O-bound):模型加载、多租户场景下的模型切换,可能导致存储I/O或网络I/O成为瓶颈。
-
- 软件栈开销 (Software Overhead):Python解释器开销、框架本身的调度开销、CUDA Kernel启动开销等,都会无形中增加延迟。
-
- 并发与调度瓶颈 (Concurrency & Scheduling):如何高效处理高并发请求,如何利用GPU空闲时间,是提升吞吐的关键。
盲目地只关注某一个点,例如只做量化,却忽视了KV Cache的内存管理,或者只用了vLLM,但模型本身可以进一步剪枝,这都是“瞎优化”的典型。真正的优化,需要从模型、引擎、系统到应用层,进行全栈考量。
系统性指南:大模型推理优化分层策略
我们将优化策略分为四个层次,层层递进,共同构建高效、低成本的大模型推理服务。
第一层:基础模型层优化
这一层是在模型训练或微调阶段就能介入的优化,对最终性能和成本影响最大。
-
- 量化 (Quantization):
-
• 原理:将模型权重和/或激活值从高精度(如FP32、FP16)降低到低精度(如INT8、INT4、甚至FP8)。显著减小模型体积,降低内存带宽需求,并能利用低精度硬件加速。
-
• 实践:
-
• 训练后量化 (Post-Training Quantization, PTQ):无需重新训练,通过校准数据集确定量化参数。简单快捷,但可能存在精度损失。适合对精度要求不那么极致的场景。
-
• 量化感知训练 (Quantization-Aware Training, QAT):在训练过程中模拟量化误差,使模型对量化更鲁棒。精度损失小,但需要重新训练或微调,成本较高。
-
• 陷阱:不是所有模型都适合直接INT8量化,某些层的敏感性高。需要评估量化对模型质量的影响。FP8(特别是E4M3和E5M2格式)正在成为新的趋势,平衡了精度和性能。
-
-
• 推荐:对于大多数企业应用,PTQ的INT8或FP8是一个很好的起点。如果精度要求极高,且有足够资源,考虑QAT。
-
- 剪枝与稀疏化 (Pruning & Sparsity):
-
• 原理:移除模型中不重要的连接、神经元或层,使模型变得稀疏。减少了模型参数量和FLOPs。
-
• 实践:分为非结构化剪枝(任意剪枝)和结构化剪枝(按行、列或块剪枝)。结构化剪枝更容易被硬件加速。
-
• 陷阱:剪枝后的稀疏模型,在通用硬件上(如标准GPU)可能难以获得实际的加速,因为稀疏计算需要专门的硬件支持或高效的稀疏算子实现。更多体现在模型存储和传输的减少上。
-
- 知识蒸馏 (Knowledge Distillation):
-
• 原理:用一个大型的“教师模型”去指导训练一个更小、更快的“学生模型”,使其在性能接近教师模型的同时,显著降低推理成本。
-
• 实践:需要大量的数据和训练周期。
-
• 推荐:这是长期来看降本增效最有效的策略之一,但投入大,适合核心业务模型。
第二层:推理引擎与框架层优化
这一层主要关注如何高效地执行模型计算图。
-
- 专用推理引擎 (Specialized Inference Engines):
-
• 原理:这些引擎(如NVIDIA TensorRT, Intel OpenVINO, ONNX Runtime)通过图优化(算子融合、层剪枝、内存优化)、硬件特定优化(利用Tensor Core等)、以及高效的Kernel实现,显著提升推理性能。
-
• 实践:通常需要将模型转换为引擎支持的中间格式(如ONNX),然后引擎会对其进行编译和优化。
-
• 推荐:TensorRT是NVIDIA GPU上的首选,尤其配合量化效果更佳。
-
- KV Cache优化 (KV Cache Optimization):
-
• 原理:Transformer模型在生成每个token时,都会重复计算Attention机制中的Key和Value。为了避免重复计算,这些K/V值会被缓存起来,称为KV Cache。然而,KV Cache会消耗大量显存,且存在碎片化问题,尤其是在多用户、动态请求长度的场景下。
-
• 实践:
-
• PagedAttention (vLLM):这是当前最有效的KV Cache管理方案之一。它借鉴了操作系统中的分页内存管理思想,将KV Cache存储在非连续的物理页中,解决了内存碎片化问题,并允许高效地共享KV Cache,显著提升了吞吐量和GPU利用率。
-
• 量化KV Cache:将KV Cache也进行低精度量化,进一步降低显存占用。
-
-
• 推荐:对于所有生成式大模型,vLLM的PagedAttention几乎是标配,能极大提升并发吞吐量。
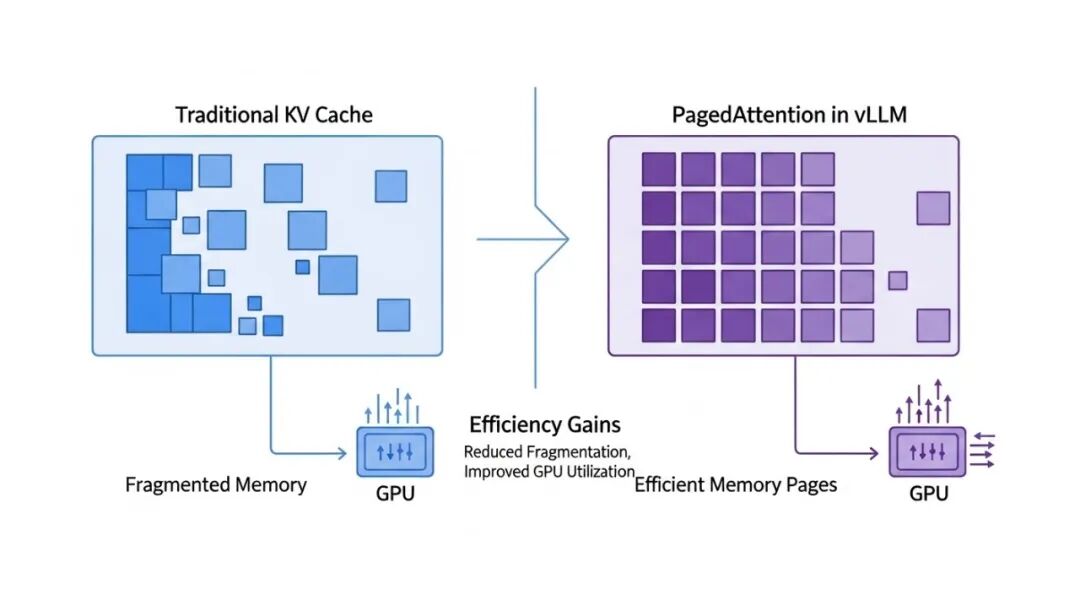
A comparison diagram illustrating the memory layout and efficiency gains of traditional KV Cache versus PagedAttention in vLLM, showing reduced fragmentation and improved GPU utilization for large language models.
-
- 动态批处理 (Dynamic Batching):
-
• 原理:GPU在处理批量请求时效率更高。动态批处理会在短时间内收集多个用户请求,将它们合并成一个批次进行推理,从而提高GPU利用率和吞吐量。
-
• 实践:需要一个高效的请求调度器来管理等待队列和批次构建。
-
• 陷阱:批处理大小过大可能导致延迟增加,需要根据业务SLA和硬件资源进行权衡。
-
- 算子融合与图优化 (Operator Fusion & Graph Optimization):
-
• 原理:将多个连续的小算子融合成一个大的Kernel,减少Kernel启动开销和内存访问。这是专用推理引擎的核心优化之一。
-
• 实践:通常由推理引擎自动完成,但对于一些自定义算子,可能需要手动编写CUDA Kernel进行融合。
第三层:系统与部署层优化
这一层关注如何将优化后的模型和引擎高效地部署到生产环境中。
-
- 分布式推理 (Distributed Inference):
-
• 原理:当模型过大,单张GPU无法承载,或者需要极致的吞吐量时,需要将模型或数据分布到多张GPU甚至多台服务器上。
-
• 实践:
-
• 张量并行 (Tensor Parallelism):将模型的单个层(如矩阵乘法)拆分到多个设备上并行计算。适用于模型巨大无法单卡加载的场景。
-
• 流水线并行 (Pipeline Parallelism):将模型的不同层分配给不同的设备,形成一个流水线。可以与张量并行结合使用。
-
• 数据并行 (Data Parallelism):每个设备加载完整模型,处理不同批次的请求。适用于高吞吐量场景,通常与其他并行策略结合。
-
-
• 陷阱:分布式推理引入了复杂的通信开销和同步问题,需要谨慎设计和实现,否则性能可能不升反降。DeepSpeed-Inference、Megatron-LM等框架提供了分布式推理的能力。
-
- Serving框架 (Serving Frameworks):
-
• 原理:提供统一的模型加载、版本管理、动态批处理、负载均衡、健康检查等服务。
-
• 实践:NVIDIA Triton Inference Server、KServe、Ray Serve等是常见的选择。它们能与各类推理引擎(TensorRT, ONNX Runtime等)无缝集成。
-
• 推荐:Triton Inference Server在NVIDIA GPU生态中表现出色,其对并发请求、动态批处理和多模型服务的支持非常成熟。
-
- 硬件选型与异构计算 (Hardware Selection & Heterogeneous Computing):
-
• 原理:选择最适合大模型推理工作负载的硬件。A100/H100等HBM容量大、算力强的GPU是首选,但成本高昂。
-
• 实践:
-
• 高性价比GPU:对于某些负载,消费级GPU(如RTX 4090)在性价比上可能优于专业卡。
-
• 定制加速器 (ASIC):如Google TPU、AI芯片创业公司的产品,针对特定模型或算子进行优化,提供极致的能效比。
-
• CPU推理:对于小模型或低并发场景,或者作为GPU的后备方案。OpenVINO在Intel CPU上表现优异。
-
-
• 推荐:根据预算、性能要求和模型大小综合考虑。通常,先用A100/H100验证方案,再考虑是否能用高性价比GPU或异构计算降低成本。
-
- 资源调度与弹性伸缩 (Resource Scheduling & Auto-scaling):
-
• 原理:在云原生环境中,利用Kubernetes等容器编排工具进行资源的弹性伸缩和高效调度。
-
• 实践:细粒度的GPU共享(如NVIDIA MIG)可以进一步提升GPU利用率,降低单个请求的成本。HPA (Horizontal Pod Autoscaler) 根据负载自动调整推理服务的实例数量。
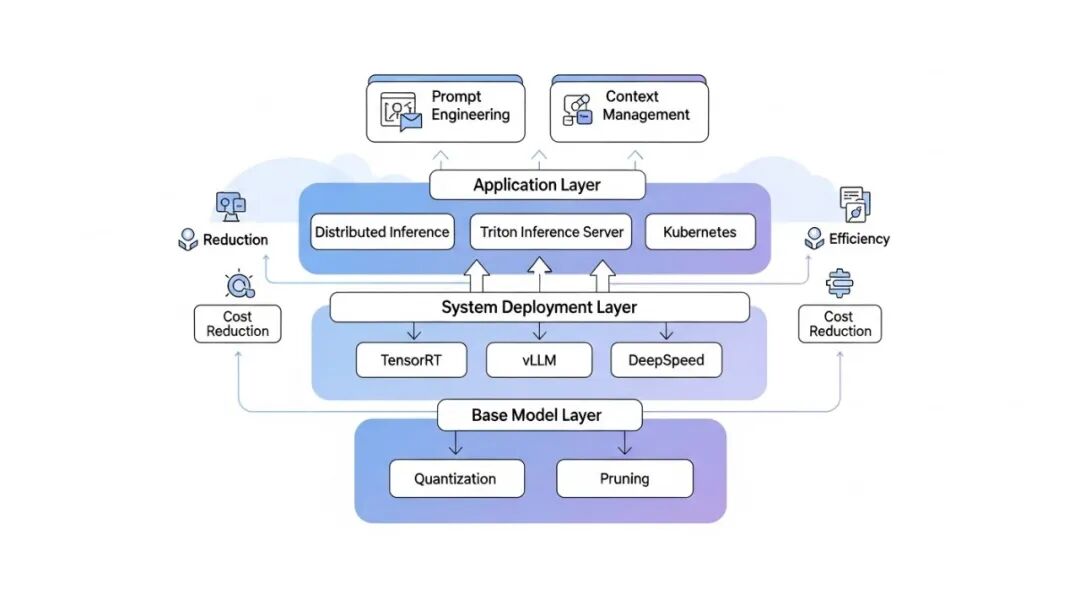
A layered architecture diagram showing enterprise LLM inference optimization, from base model (quantization, pruning) to inference engine (TensorRT, vLLM, DeepSpeed) to system deployment (distributed inference, Triton Inference Server, Kubernetes) and application (prompt engineering, context management). Arrows indicate data flow and optimization impact, with a focus on cost reduction and efficiency.
第四层:数据与应用层优化
这一层虽然不直接改变模型或推理引擎,但能从源头优化输入,减少不必要的计算。
-
- Prompt工程 (Prompt Engineering):
-
• 原理:优化用户输入的Prompt,使其更简洁、更高效地引导模型生成期望的输出。
-
• 实践:减少冗余信息,精炼指令,控制输出长度。
-
• 推荐:这是最简单也最容易被忽视的优化,却能显著减少token消耗和生成时间。
-
- 上下文管理与截断 (Context Management & Truncation):
-
• 原理:大模型的上下文窗口有限且处理长上下文的成本更高。在将用户输入传递给模型之前,智能地管理和截断上下文。
-
• 实践:对于对话历史,可以采用滑动窗口、摘要或RAG (Retrieval Augmented Generation) 方式,只保留最相关或最重要的信息。
-
• 推荐:结合业务场景,设计合适的上下文管理策略,避免将不必要的长文本送入模型。
总结
企业大模型推理优化是一个复杂的系统工程,没有银弹。它需要你像一个外科医生,精准诊断瓶颈,然后像一个建筑师,系统性地规划和实施多层次的优化策略。从模型层面的量化蒸馏,到引擎层的KV Cache管理与图优化,再到系统层的分布式部署与高效调度,每一步都至关重要。别再盲目尝试了,理解你的瓶颈,选择合适的工具,才能真正实现降本增效。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)