搭建RAG系统 文档处理流水线
摘要:RAG(检索增强生成)系统的文档处理流程分为四个关键步骤:1)文档采集与预处理,支持多格式加载和文本清洗;2)文档分块与向量化,采用语义分块策略和领域专用嵌入模型;3)向量存储与索引构建,根据场景选择Chroma/FAISS等数据库;4)检索优化,结合关键词与语义检索,并动态调整上下文。流程强调领域适配性,建议定期评估召回率和延迟指标进行迭代优化。典型实现使用LangChain工具链完成文档
·
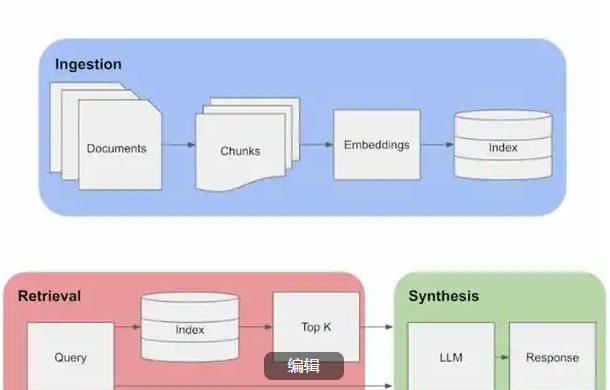
RAG(检索增强生成)系统的核心在于高效处理文档并构建可实时检索的知识库。以下是分步骤的文档处理流水线设计,涵盖从数据采集到最终检索优化的全流程,重点突出技术细节与最佳实践。
一、文档采集与预处理
1. 数据源接入
- 支持格式:PDF、Word、HTML、Markdown、CSV、数据库(MySQL/PostgreSQL)、API接口等。
- 工具推荐:
- 通用文档解析:
unstructured库(支持多种格式)、pdfplumber(PDF解析)、langchain的DocumentLoaders模块。 - 结构化数据:
pandas(CSV/Excel)、SQLAlchemy(数据库连接)。
- 通用文档解析:
- 示例代码:
from langchain.document_loaders import UnstructuredPDFLoader loader = UnstructuredPDFLoader("medical_report.pdf") documents = loader.load() # 返回Document对象列表
2. 文本清洗
- 操作内容:
- 去除HTML标签、页眉页脚、重复空白行。
- 统一编码(UTF-8)、标准化日期格式。
- 处理特殊字符(如
替换为空格)。
- 工具推荐:
BeautifulSoup(HTML清洗)、re(正则表达式)、langchain的TextSplitter(分块前清洗)。
二、文档分块与向量化
1. 文本分块
- 分块策略:
- 固定大小:按字符数(如512字符/块)或Token数(如GPT-3的2048 Tokens)。
- 语义分块:基于句子边界或段落分割(如
nltk的sent_tokenize)。 - 混合策略:优先按语义分割,不足时填充相邻内容。
- 重叠处理:相邻块保留10%-20%重叠内容,避免上下文断裂。
- 示例代码:
from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=512, # 字符数 chunk_overlap=64, separators=["\n\n", "\n", " ", ""] ) chunks = text_splitter.split_documents(documents)
2. 向量化处理
- 嵌入模型选择:
- 通用模型:
sentence-transformers/all-MiniLM-L6-v2(速度快)、BAAI/bge-base-en(中文友好)。 - 领域模型:
bio-clinical-bert(医学)、legal-bert(法律)。
- 通用模型:
- 批量处理:使用GPU加速(如
torch的DataLoader),单批次建议≤1024个向量。 - 示例代码:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = model.encode([chunk.page_content for chunk in chunks]) # 生成向量
三、向量存储与索引构建
1. 向量数据库选择
| 数据库 | 优势 | 适用场景 |
|---|---|---|
| Chroma | 轻量级、Python原生支持 | 本地开发、小规模数据 |
| FAISS | 极高性能、支持GPU加速 | 大规模数据、高并发检索 |
| Pinecone | 全托管服务、无需运维 | 企业级应用、需要高可用性 |
| Qdrant | 支持过滤条件、混合检索 | 需要复杂查询的场景 |
2. 索引构建
- 关键参数:
- 距离度量:余弦相似度(文本)、欧氏距离(数值)。
- 索引类型:
HNSW(高效近似最近邻搜索)、IVF(倒排文件索引)。
- 示例代码(Chroma):
from chromadb import Client
client = Client()
collection = client.create_collection(name="medical_docs")
collection.add(
documents=[chunk.page_content for chunk in chunks],
embeddings=embeddings,
ids=[str(i) for i in range(len(chunks))]
)
四、检索优化与增强
1. 混合检索策略
- 关键词检索:
BM25(如rank_bm25库)快速定位候选文档。 - 语义检索:向量数据库返回语义相似文档。
- 融合策略:
- 加权求和:
score = 0.7 * BM25_score + 0.3 * Cosine_similarity。 - 重排序模型:使用交叉编码器(如
cross-encoder/ms-marco-MiniLM-L-6-v2)对候选文档重新评分。
- 加权求和:
- 示例代码:
from rank_bm25 import BM25Okapi corpus = [chunk.page_content for chunk in chunks] bm25 = BM25Okapi(corpus) bm25_scores = bm25.get_scores("acute myocardial infarction") # 关键词检索
2. 上下文增强
- 元数据附加:为文档添加标题、章节、来源URL等元数据,支持过滤查询。
- 动态上下文窗口:根据问题复杂度调整检索文档数量(如简单问题检索5篇,复杂问题检索20篇)。
五、性能监控与迭代
1. 评估指标
- 检索召回率:
Recall@K(如Recall@10表示前10个结果中包含正确答案的比例)。 - 端到端延迟:从用户提问到生成回答的总时间(目标<3秒)。
- 用户反馈:通过“点赞/踩”按钮或人工标注收集错误案例。
2. 迭代优化
- 知识库更新:定期(如每周)重新索引新增文档。
- 模型调优:根据评估结果调整分块大小、检索策略或嵌入模型。
六、完整流水线示例
# 1. 文档加载与清洗
from langchain.document_loaders import UnstructuredPDFLoader
loader = UnstructuredPDFLoader("clinical_guideline.pdf")
documents = loader.load()
# 2. 文本分块
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=64)
chunks = text_splitter.split_documents(documents)
# 3. 向量化
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("bge-base-en")
embeddings = model.encode([chunk.page_content for chunk in chunks])
# 4. 存储到向量数据库(Chroma)
from chromadb import Client
client = Client()
collection = client.create_collection(name="clinical_knowledge")
collection.add(
documents=[chunk.page_content for chunk in chunks],
embeddings=embeddings,
metadatas=[{"source": chunk.metadata["source"]} for chunk in chunks] # 附加元数据
)
# 5. 检索示例
query = "What is the recommended dosage of aspirin for acute MI?"
query_embedding = model.encode(query)
results = collection.query(
query_embeddings=[query_embedding],
n_results=10,
where={"source": {"$contains": "ESC"}} # 过滤条件
)
七、关键注意事项
- 成本权衡:向量数据库的存储成本与检索性能成正比,需根据业务规模选择。
- 领域适配:医学、法律等场景需使用专用嵌入模型和分块策略。
- 实时性要求:高频交易等场景需结合缓存(如Redis)或预计算热门问题的答案。
通过以上步骤,可构建一个高效、可扩展的RAG文档处理流水线,支持实时检索与准确回答。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献98条内容
已为社区贡献98条内容

所有评论(0)