AI大模型的前世今生:Deepseek底层逻辑和技术详解
AI大模型的发展,既是技术的跃迁,更是人类智慧的延伸。从DeepSeek的崛起到全球开源社区的繁荣,我们见证了一个更开放、更智能的时代正在到来。未来,AI将不仅是工具,而是成为人类探索未知、实现普惠的伙伴。让我们以技术为舟、以合作为桨,共同驶向智能时代的星辰大海!
随着Deepseek年初的爆火,短短四个月时间,AI大模型的使用频率越来越多,受众也越来越广泛,并延伸到各个行业的不同年龄群体:小学生写作文、中学生解答数学题、大学生毕业设计、职场人日常办公、VLOG博主制作短视频……
前排提示,文末有大模型AGI-CSDN独家资料包哦!
最近,看到不少非计算机专业朋友反映的问题:
“市面上这么多AI大模型,到底哪家强?”
“经常听一些大模型赋能行业的讲座,内容涉及到的专业名词,如:Transformer、LLM、Embedding都是什么意思,能否可以通俗的解释下?”
为了帮大家更好地理解大模型、使用大模型,下面通过一些类比方法,并结合个人体会,详细梳理下AI大模型底层逻辑和技术,希望能让大家通俗来理解。
一、大语言模型(Large Language Modeling,LLM)
语言模型是计算机发展最早的一种技术形态,它的终极目标是:对于任意的词序列,计算出这个序列是一句话的概率。
其实,我们每天都和语言模型打交道:
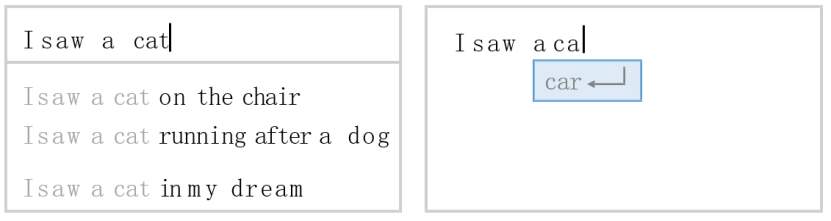
那么,如何让计算机理解人类语言呢?
—— 编码
早期,计算机采用二进制编码,因此对单词和文字的分类变量编码方法采用One-hot Encoding(独热编码),简单来说,就是通过0-1二元编码方式,对每个单词/汉字加以区分,且每个编码只有1个1;
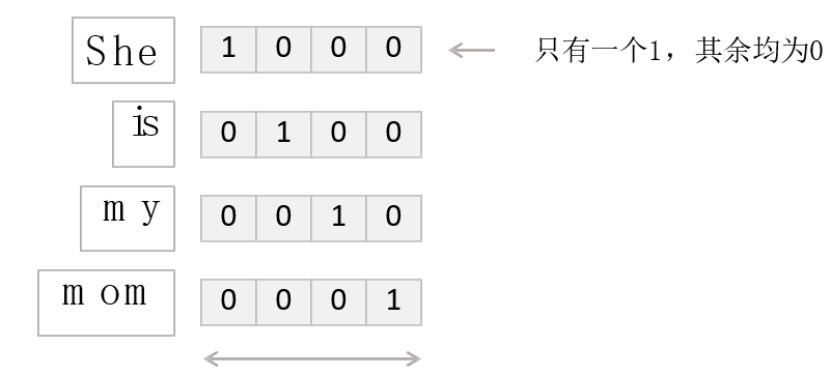
这种编码方法存在两个明显的缺点:
高维稀疏性:当分类变量的类别数量(基数)很大时,One-hot编码会生成大量新特征。例如,一个有1000个类别的变量会被转换为1000维的稀疏矩阵。高维数据会增加内存占用和计算时间,尤其是在处理大规模数据集时。由此,导致了计算效率低。
忽略类别间的关系:One-hot编码将每个类别视为独立的二元特征,无法捕捉类别之间的潜在关系。例如,苹果、香蕉、橘子,都属于水果的关联性。
因此,就出现了单词向量化(Word Embedding)——用一个低维的词向量表示一个词,能使距离相近的向量对应的物体有相近的含义;

比如:判别是否能在水中游泳的列向量,鲸鱼、海豚、企鹅的向量值相近,且接近于1),区别于不会游泳的鹦鹉(接近于0);
同理,判别是否可以飞翔的列向量,鹦鹉的向量值接近于1,而其他动物则赋值较低。
通过这种编码方式,就可以将不同单词存储在一个高维的向量空间,在向量空间中,相近的单词具有更高的关联性;
Word Embedding也是当前大模型的主流编码方法,一个20维的向量用one-hot和word embedding的方法,前者只能表示20个单词,而后者通常可以表示几千甚至上万个!维度越高,单词在向量空间划分的越细致,其内涵也越丰富;(将单词看做一个人,可以理解为每个人都可以被赋予成百上千个标签属性)。
当前,部署AI大模型时,经常看到的“嵌入模型”,就是基于Embedding技术方法;
特别是针对大量学习资料的大模型部署,通过嵌入模型的编码,对用户提问解码固定到一个确定的向量空间位置,即可快速在向量空间内检索到与之相近的核心资料,再进行作答。
到这里,有人可能会问:向量化可以看做将单词分类,那它又是如何理解不同单词的含义呢?
—— 做“完形填空”

结合句子语境我们可以猜测:tezgüino是一种由玉米制作的酒精类饮料;

通过让计算机做“完形填空”,便可以让计算机理解人类语言,并通过判断给出概率最高的答案。
语言模型的技术演化,经历了三个阶段:基于统计的N-gram:、基于神经网络的LSTM/GRU和Transformer。
阶段1:基于统计的N-gram:(1970 after)
N-gram如同一个「词语联想的猜谜游戏」。它通过统计历史文本中词组的出现频率(例如“小猫抓老鼠”拆解为“小→猫→抓→老→鼠”的组合概率),预测下一个词该填什么。

·马尔可夫假设:像拼图时只看前几块的颜色,忽略更远的图案(例如2-gram只参考前一个词);
·数据稀疏性:若遇到生僻组合(如“猫抓大象”),就像拼图缺了一块,只能靠“平滑技术”强行估算。
特点:简单直接但笨拙,可以看做用纸质词典查词,适合早期语音识别和简单翻译。
阶段2:基于神经网络的LSTM/GRU (2000 after)
LSTM/GRU模型用循环神经网络(RNN)处理序列,引入门控机制(遗忘门、输入门、输出门)缓解梯度消失。它如同一个「带记忆笔记本的作家」,用RNN逐字阅读句子,并通过门控机制决定记住或忘记哪些信息。
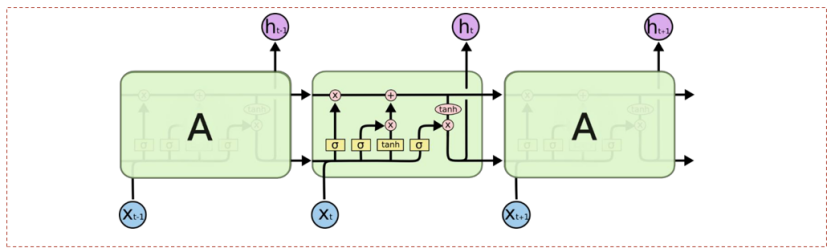
·遗忘门:像用荧光笔划掉日记中不重要的内容(例如忘记“今天天气晴”中的“晴”);
·LSTM:通过细胞状态长期记忆上下文(如句子主题);
·GRU:简化版LSTM,合并门控参数,提升训练效率;
·记忆细胞:像在笔记本上长期记录故事主线(如“主角是侦探”),避免遗忘开头。
特点:能处理长句子,但写日记必须一字一句来(无法并行),速度较慢,曾用于早期智能助手和文本生成。
N-gram →神经网络:
突破:从统计表驱动转向参数化模型,引入分布式语义表示。
应用:机器翻译(如早期Google Translate)、文本生成。
阶段3:Transformer (2017 after)
Transformer模型完全依赖自注意力机制(Self-Attention),并行处理全序列。如同一个「同时指挥整个乐团的作曲家」。它抛弃逐字处理,用自注意力机制让每个词瞬间与全文对话。
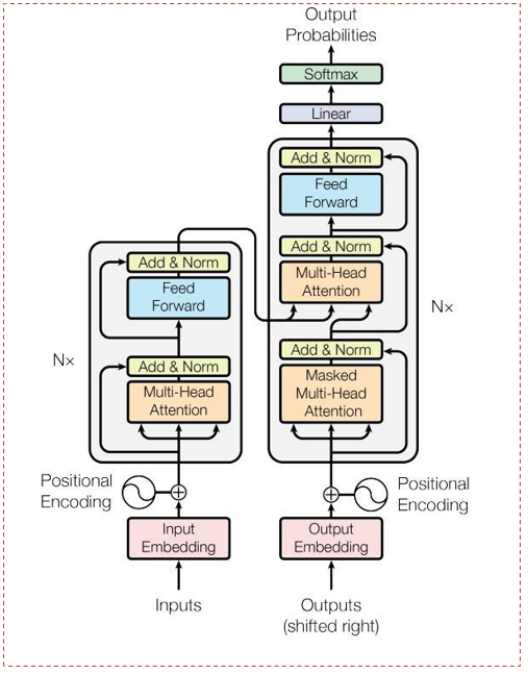
·多头注意力(Multi-Head Attention):从不同子空间捕捉多样依赖关系。像多个乐手分工合作,有人听旋律,有人看节奏,综合所有信息演奏。
·位置编码(Positional Encoding):为无顺序的注意力机制注入位置信息。像给乐谱加上页码,让模型知道“第一小节”和“最后一小节”的位置关系。
·残差连接(Add & Norm):稳定深层网络训练。像在乐谱间架设高速公路,确保深层网络的信息流畅传递。
特点:并行处理整段文本,支撑了Deepseek、ChatGPT等AI大模型。
LSTM/GRU → Transformer:
突破:从序列串行计算转向全序列并行,支撑大规模预训练。
应用:BERT(双向编码)、GPT系列(自回归生成)、多模态模型。
语言模型的三个发展阶段,从局部统计到全局神经网络,再到并行化自注意力的三次跃迁。每一代模型都在处理效率、语义理解和长文本建模上实现突破,最终推动AIGC技术的爆发式发展。
毫不夸张的说,Transformer就是大语言模型的基石!
二、Transformer
自2017年,Google研究团队在NIPS上发表的里程碑论文《Attention Is All You Need》,彻底改变了自然语言处理的格局。这篇论文的核心贡献是首次提出了Transformer模型,一种完全依赖注意力机制(Attention)的架构,摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),目前引用量超过15万+,成为21世纪最具影响力论文,并被纳入NeurIPS/ACL/ICML等顶会“史上最具影响力论文”榜单。

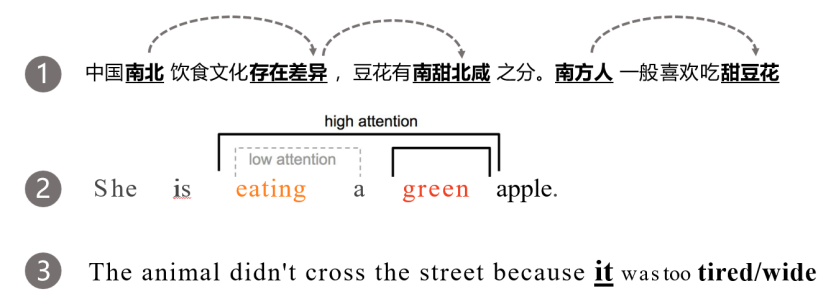
在理解语言任务时,注意力机制本质上是捕捉单词间的关系;
以第二句话为例:eating和apple、green和apple是两组强相关词汇,而eating和green是一组弱相关词汇。
在理解图像任务时,注意力机制本质上是一种图像特征抽取;

以上图为例,注意力机制是通过类似素描方法(Sketch)提取图像的轮廓特征,再通过梯度方法(Gradient)利用明暗变化强化边缘信息;
这两种方法分别模拟了注意力机制在特征抽取中的两种关键能力——前者像用画笔勾勒结构本质,剥离冗余信息,后者如同放大镜聚焦局部差异,凸显关键区域;
这种从复杂原图中动态筛选和强化核心特征的逻辑,正是注意力机制在计算机视觉中的本质:它不依赖完整解析所有像素,而是模仿人类视觉的「选择性关注」,从纷繁背景中捕捉语义主干,让模型学会「看重点」。
再来说说Transformer的训练机制,训练的流程如下:
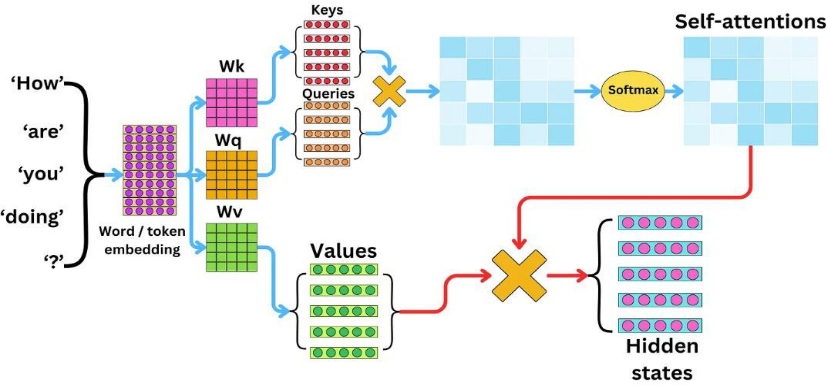
这里面涉及了Attention论文中最核心的公式:
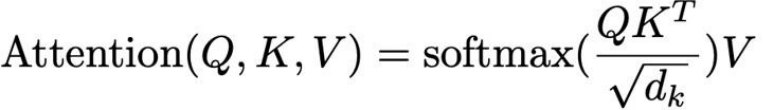
我们假设一个场景:你在图书馆想找一本关于“机器学习基础”的书;
Query变量的含义是描述要找的书(如:需要一本涵盖概率论和代码实践的机器学习教材);Key变量的含义是书的索引编号,图书管理员给图书高效编码(如:TP181.C66对应机器学习分类);而Value变量则表示内容的抽取(如书中讲解梯度下降的章节)
对应NLP(自然语言处理)任务:模型需要理解句子中每个词(“How are you doing?”)的语义,并找到词与词之间的关联。
Transformer模型提出后,大模型迎来了突破性进展,机器学习的范式发生了变化,开始逐渐转向深度学习,并进入了预训练时代,强调训练数据规模和质量的重要性,即「大力出奇迹」:投喂大量的数据,模型的理解能力会有显著提升。
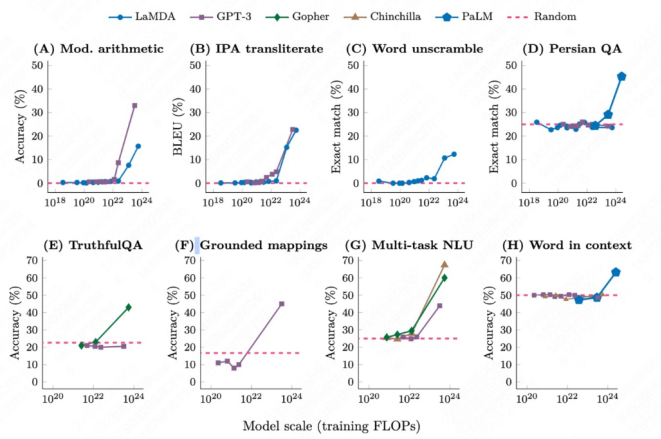
下图对几种早期机器学习和深度学习模型的识别精度进行了比较,可以看到:当投喂的数据量超过10^22时,大模型突然“开窍了”!
研究发现,当模型参数规模达到某个临界点时,模型会突然展现出之前不具备的能力,比如解决复杂的数学问题或进行多步骤的逻辑推理,这种现象也被称为「涌现」(Emergence)。
基于Transformer架构,大模型的发展出现了两种技术路径:
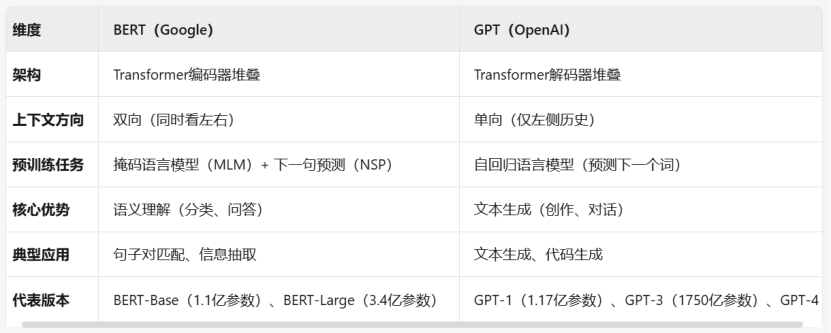
以Google AI为代表的BERT(Bidirectional Encoder Representations from Transformers)技术路径,2018年10月由Jacob Devlin等人在论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》中首次提出;
以OpenAI为代表的GPT(Generative Pre-trained Transformer)技术路径,2018年6月Alec Radford和Ilya Sutskever(OpenAI联合创始人,深度学习先驱)等人在论文《Improving Language Understanding by Generative Pre-training》中提出初代GPT,截至目前已迭代至GPT-4。

下表对比了两种技术路线的区别,简单来说:BERT更像是「理解专家」,它的技术从双向理解文本,强调“倒背如流”的重要性。这种训练让它擅长理解语义,比如判断两个句子是否相关,或者从文章中提取答案。但缺点是无法直接写文章——就像学霸会做题,但未必会写小说。
而GPT更像是「创作达人」,它在写作文时只能按顺序一个个字往下编(单向),每次只根据已写的内容预测下一个词。这种训练让它能生成流畅的对话或故事,比如你问“如何做蛋糕?”,它能一步步编出配方。但缺点是容易“偏题”——如果开头写错,后面可能一路跑偏。
时至今日,BERT和GPT系列仍是两大主流AI大模型,基于它们的技术路径,而后陆续出现了很多衍生模型,但两者的应用场景和影响力已发生显著分化。GPT侧重C端产品,而BERT则提供B端服务;许多企业用BERT处理信息抽取,再用GPT生成总结报告,实现“理解+生成”闭环。
对于海量数据的预训练过程,靠人工是无法完成的,于是学者提出了自监督学习;
Masked Langauge Modeling(MLM)模型就是一种文本自监督学习方法,目前广泛应用于自然语言处理(NLP)中,尤其在BERT预训练模型中扮演核心角色。其核心思想是通过遮盖文本中的部分内容,让模型学习预测被遮盖的部分,从而理解语言的上下文关系和语义表示。

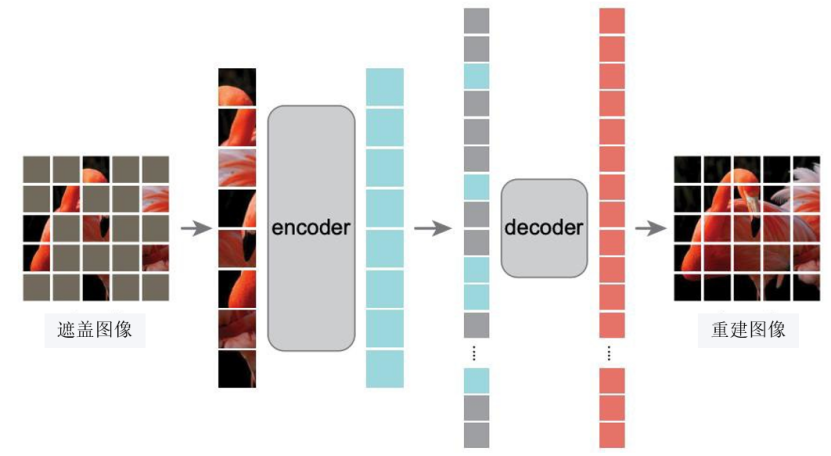
对于图像预训练方法的,在这里不得不提到我国著名人工智能领域专家何恺明教授,其团队在2021年11月发表的论文《Masked Autoencoders Are Scalable Vision Learners》(NeurIPS 2021),首次提出了Masked Autoencoders(MAE),成为计算机视觉领域自监督学习的里程碑。
该研究通过引入高比例掩码自编码架构(MAE),成功克服了传统视觉模型中高掩码率导致特征表征失效的瓶颈问题,将有效掩码率从自然语言处理领域的15%提升至75%以上。实验表明,仅使用25%的可见图像块进行训练,MAE在ImageNet-1K数据集微调后仍能达到87.8%的top-1分类准确率,这一突破性进展有力回应了学术界对“高掩码率破坏图像语义连续性”的理论性质疑,为视觉自监督学习开辟了新范式。
打开谷歌学术搜索Kaiming He,显示的数字是“703523”,这是何恺明教授的论文引用量,在整个人工智能学界,排名第三,仅次于被誉为“深度学习之父”的两位元老级前辈——Yoshua Bengio和Geoffrey Hinton。

那么,训练Transformer的通用之力是什么?
——数据、模型、算力
数据是燃料、模型是引擎、算力是加速器!
大数据、大模型、大算力下,“共生则关联”原则实现了统计关联关系的挖掘。
以早期的ChatGPT 3模型的预训练为例:
数据:训练中使用了45TB数据、近1万亿个单词(约1351万本牛津词典所包含单词数量)以及数十亿行源代码。
模型:包含了1750亿参数,将这些参数全部打印在A4纸张上,一张一张叠加后,叠加高度将超过上海中心大厦632米高度。
算力:ChatGPT的训练门槛是1万张英伟达V100芯片、约10亿人民币。

说到这里,不得不提一下英伟达,2025年的英伟达的全球市值高达1.2万亿美元,是AI算力领域绝对统治者,2024年最高点曾超过3.7万亿美元,一度超过微软和苹果,登顶全球市值最高公司;
据《纽约时报》报道,2005年时任英特尔CEO的Paul Otellini曾提出以20亿美元收购当时尚不出名的GPU公司英伟达,但在英特尔董事会的反对下,这场收购计划最终以失败告终;
如今CPU市场日暮西山,英特尔市值已经跌破1000亿美元大关,仅是英伟达的1/13,不禁让人唏嘘。
回到正题,再梳理一下当前大模型发展脉络。
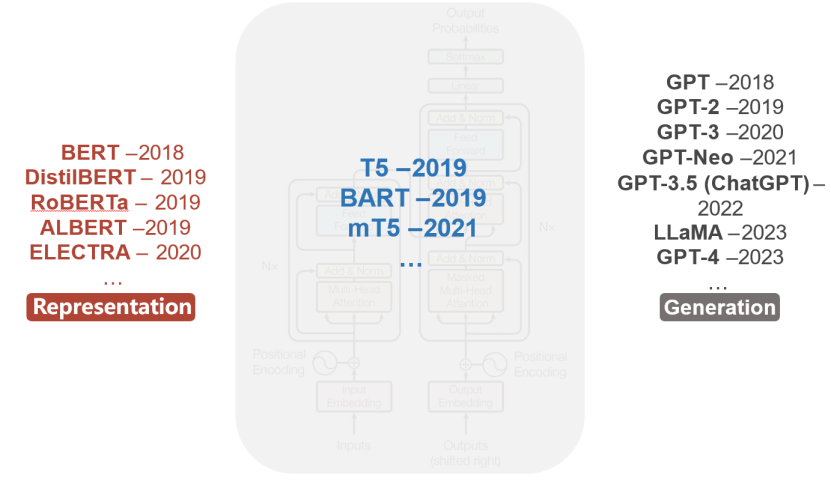
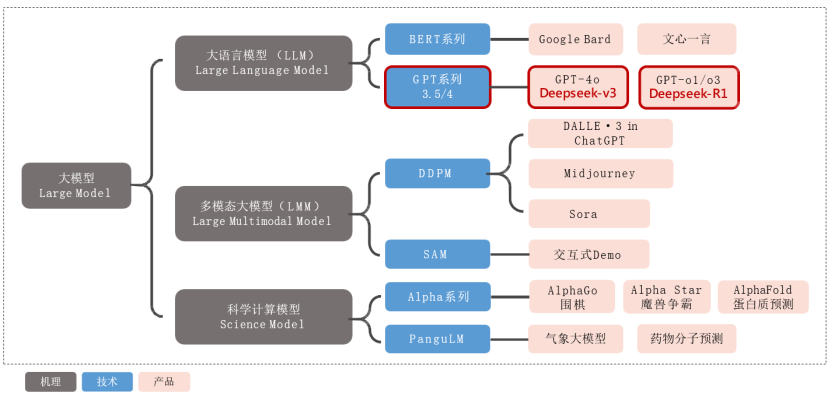
以大模型(Large Model)为核心,向下延伸出三大分支——大语言模型(LLM)、多模态大模型(LMM)和科学计算模型(Science Model)。
大语言模型聚焦文本智能,分为BERT系列(如Google Bard、文心一言)与GPT系列(涵盖GPT-3.5/4、GPT-4o/o1/o3及中国团队的DeepSeek-v3/R1),展现从基础理解到生成式对话的技术跃迁;
多模态大模型突破单模态局限,通过DDPM技术路径(如DALL·E3、Midjourney、Sora)实现文生图/视频,借助SAM模型的交互式分割能力赋能工业与医疗;
科学计算模型则探索AI与硬核科学的融合,既有Alpha系列(AlphaGo围棋博弈、AlphaStar游戏策略、AlphaFold蛋白质预测)在复杂系统建模中的突破,也有PanguLM在气象预测与药物研发中的实用化成果。
三、ChatGPT
前文提到基于Transformer架构,大模型出现了“涌现”能力,最早是从GPT-3模型开始,也正是从这时起,人们才真正开始关注大语言模型的能力价值所在。
如今,OpenAI虽然没有开源,但其每年发布的技术白皮书仍是行业的风向标,蕴藏着非常有价值的技术细节。
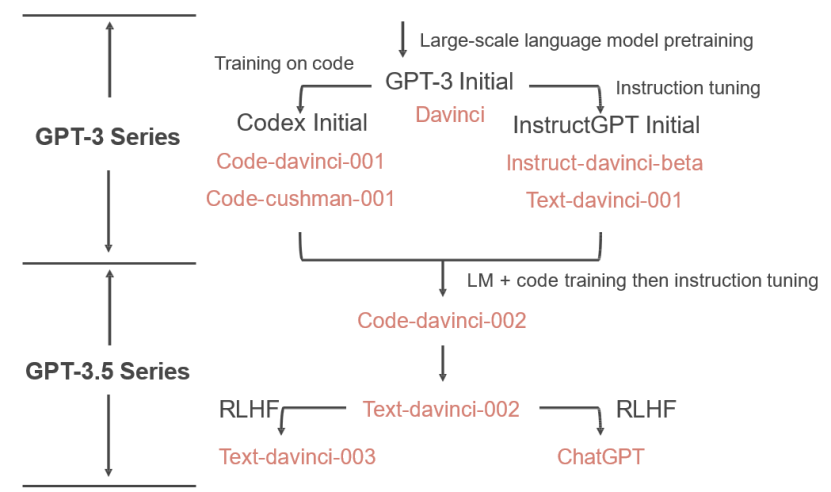
GPT-3 Initial(通过大规模预训练,初代GPT-3展示了三个重要能力)
语言生成:来自语言建模的训练目标(说人话);
世界知识:来自3000亿单词的训练语料库(百晓生);
上下文学习:上下文学习可以泛化,仍然难以溯源(触类旁通)。
初代GPT-3表面看起来很弱,但有非常强的潜力,展示出极为强大的“涌现”能力。

2020-2021年,OpenAI投入了大量的精力通过代码训练和指令微调来增强GPT-3。
Codex Initial(思维链)
使用思维链进行复杂推理的能力是代码训练的一个神奇副产物;
InstructGPT Initial(指令微调)
使用指令微调将GPT-3.5的分化到不同的技能树(数学家/程序员/…)。
Code-davinci-002(人类对齐)
指令微调牺牲性能换取与人类对齐(“对齐税”)
2022.11月,RLHF(基于人类反馈的强化学习的指令微调)
翔实的回应、公正的回应、拒绝不当问题、拒绝其知识范围之外的问题。
随着大模型技术的进步成熟,终于在2022年11月30日,OpenAI首席执行官Sam Altman通过推特正式发布ChatGPT;
后来,业内将这一天称之为「人工智能的IPHONE时刻」。ChatGPT模型基于GPT-3.5架构,支持对话交互,产品一经发出,迅速火爆全网,短短5天用户破百万,两个月用户破亿!(此前TikTok需9个月、Instagram需2.5年)。
随着多模态大模型的技术突破,OpenAI陆续发布了GPT-4、GPT-4o模型。

2023年6月,GPT-4模型发布,大模型从“听、说”,到“看”。

2024年6月,GPT-4o模型的发布,再次震撼业界,其能力已经达到了文科博士生的水平。

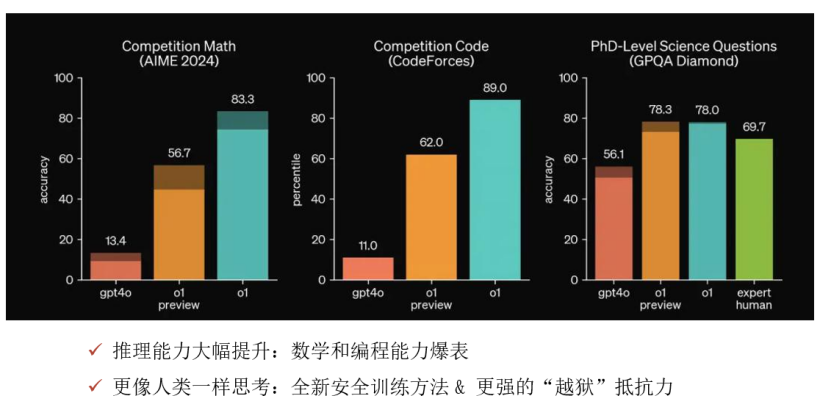
3个月后,2024年9月,GPT-o1模型发布,相比于GPT-4o,大模型的推理能力得到大幅提升,能力达到了理科博士生的水平,即使是高数题,也能迎刃而解。
四、DeepSeek
就在大家觉得,这场AI大模型的竞赛,美国将遥遥领先之时,2025年初,随着DeepSeek震撼的发布而打破!
2025年1月15日,杭州深度求索公司梁文锋团队推出了DeepSeek,上线两周下载量超1.1亿次,周活跃用户峰值达9700万。
1月27日,发布的DeepSeek-R1模型,在数学和编程测试中比肩GPT-o1,成本仅为后者的几十分之一!
根据OpenAI最新15页报告,DeepSeek缩小了中美AI差距;同时,DeepSeek也以一己之力改变了开源和闭源的力量对比,从6~12个月的代差缩短到1~3个月。
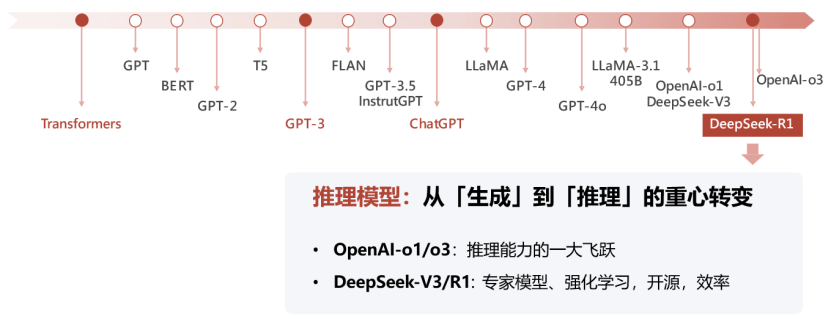

客观来说,DeepSeek模型并非是颠覆性基础理论创新,依然是Transformer-based;
其最大的贡献是对算法、模型和系统等进行的系统级协同工程创新,打破了大语言模型以大算力为核心的预期天花板,为受限资源下探索通用人工智能开辟了新的道路。
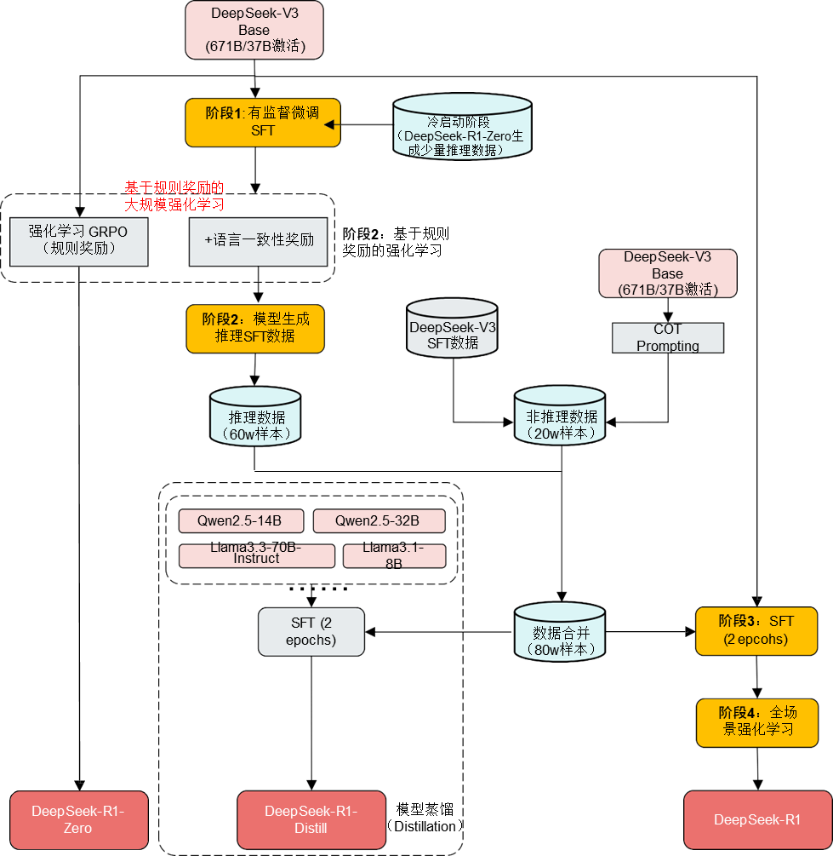
DeepSeek大模型,按阶段可细分为4种类型:
ŸStep 1:DeepSeek-V3 Base(基础生成模型)
ŸStep 2: DeepSeek-R1-Zero(推理模型初试)
ŸStep 3: DeepSeek-R1(推理横型大成)
ŸStep 4: DeepSeek-R1-Distill(R1蒸馏小模型)
DeepSeek-V3 Base对标GPT-4o(文科博士生):
混合专家模型:创新提出了“算法蒸馏”的概念,V3基座模型总共有6710亿参数,但是每次token仅激活8个专家、370亿参数(约5.5%),大大提高了响应速度。
极致的工程优化:多头潜在注意力机制(MLA),使用FP8混合精度,DualPipe算法提升训练效率,将训练效率优化到极致,显存占用为其他模型的5%-13%。
DeepSeek-R1-Zero赋予DeepSeek-V3最基础的推理能力:
R1-Zero使用DeepSeek-V3-Base作为基础模型,直接使用GRPO进行强化学习来提升模型的推理性能,模型包括:准确度奖励(Accuracy rewards)、格式奖励(Format rewards)。
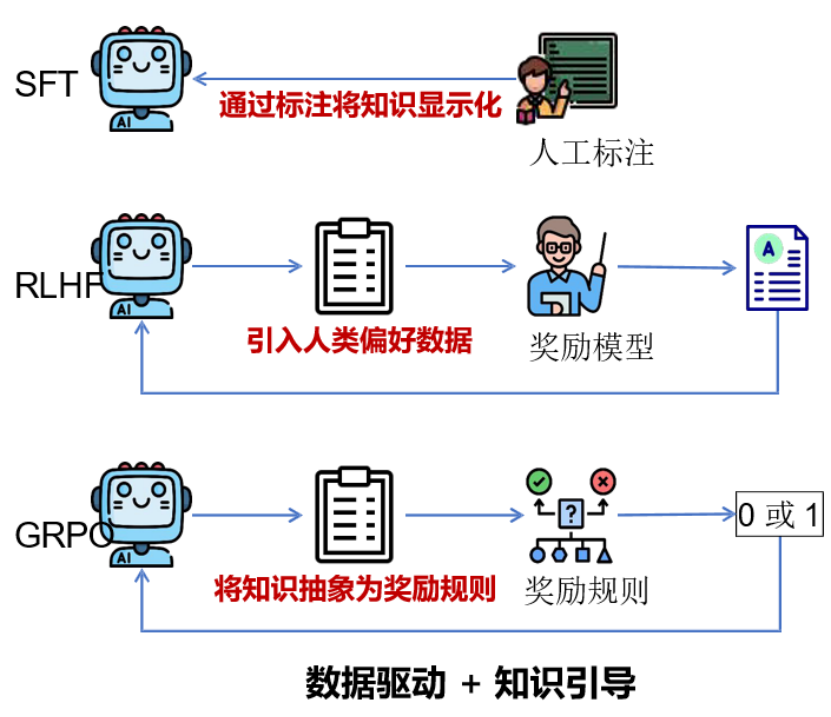
上图是DeepSeek-R1-Zero推理模型的训练框架,融合数据驱动与知识引导的双重策略——SFT(监督微调)利用人工标注显式编码知识,RLHF(人类反馈强化学习)引入偏好数据优化对齐,GRPO(规则抽象强化学习)将专家经验转化为0/1奖励规则,形成“人工标注修正基础能力+强化学习激发高阶推理”的协同训练范式,最终构建出兼顾准确性、逻辑性与可解释性的通用推理智能体。
DeepSeek-R1对标OpenAI-o1(理科博士生):
阶段1:DeepSeek-R1-Zero生成少量推理数据+SFT =>为V3植入初步推理能力(冷启动)
阶段2:根据规则奖励直接进行强化学习(GRPO)训练=>提升推理能力(多轮迭代,获取大量推理数据)
阶段3:迭代生成推理/非推理样本微调=>增强全场景能力
阶段4:全场景强化学习=>人类偏好对齐(RLHF)
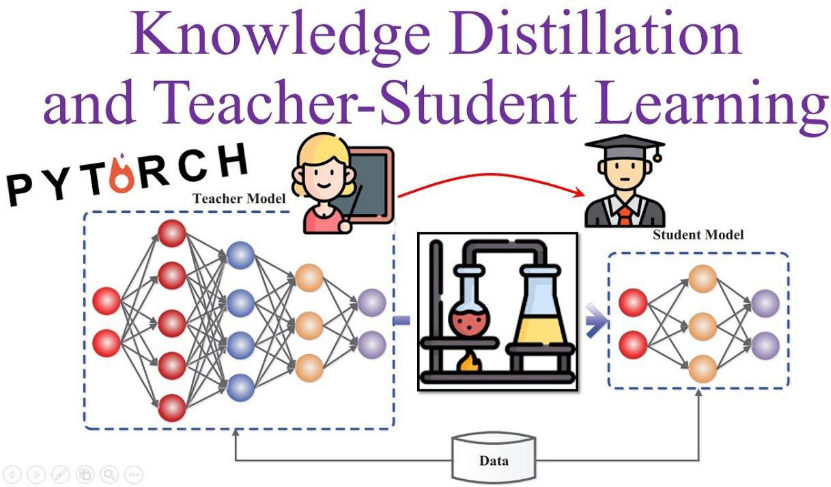
DeepSeek-R1-Distill模型:(与DS-R1模型相比,像老师与学生的关系):
(1)基于各个低参数量通用模型(千问、Llama等);
(2)使用DeepSeek-R1同款数据微调;
(3)大幅提升低参数量模型性能,(671亿→7亿参数),手机也能跑AI。
DeepSeek-R1-Distill模型对知识进行蒸馏,就像老师教学生“解题思路”,不仅给答案(硬标签),还教“为什么”(软标签)。
结语:AI大模型的发展,既是技术的跃迁,更是人类智慧的延伸。从DeepSeek的崛起到全球开源社区的繁荣,我们见证了一个更开放、更智能的时代正在到来。未来,AI将不仅是工具,而是成为人类探索未知、实现普惠的伙伴。让我们以技术为舟、以合作为桨,共同驶向智能时代的星辰大海!
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)