CV-MLLM经典论文解读| OPERA: Alleviating Hallucination in Multi-Modal Large Language Models via Over-Trust
这篇论文介绍了一种名为OPERA的新方法,旨在减轻多模态大型语言模型(MLLMs)中的幻觉问题。幻觉问题是指模型在用户给出的图像和提示中生成错误陈述,例如产生不相关或无意义的回应,错误识别图像中不存在的对象的颜色、数量和位置。OPERA通过在beam-search解码过程中引入过度信任惩罚项和回顾分配策略,有效地减少了幻觉问题,而无需额外的数据、知识或训练。
论文标题:
OPERA: Alleviating Hallucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection-Allocation
OPERA:通过过度信任惩罚和回顾分配来缓解多模态大型语言模型中的幻觉
论文链接:
Link-Context Learning for Multimodal LLMs论文下载
论文作者:
Qidong Huang1,2,*, Xiaoyi Dong2,3, Pan Zhang2, Bin Wang2, Conghui He2, Jiaqi Wang2, Dahua Lin2, Weiming Zhang1, Nenghai Yu1
内容简介:
这篇论文介绍了一种名为OPERA的新方法,旨在减轻多模态大型语言模型(MLLMs)中的幻觉问题。幻觉问题是指模型在用户给出的图像和提示中生成错误陈述,例如产生不相关或无意义的回应,错误识别图像中不存在的对象的颜色、数量和位置。OPERA通过在beam-search解码过程中引入过度信任惩罚项和回顾分配策略,有效地减少了幻觉问题,而无需额外的数据、知识或训练。
关键点:
1.问题背景:
多模态大型语言模型(MLLMs)在实际应用中面临幻觉问题,这限制了它们作为可信赖助手的使用。
2.现有方法的局限性:
现有的减轻幻觉问题的方法需要额外的训练数据、外部知识或模型,这增加了额外的成本。

3.OPERA方法介绍:
- OPERA基于过度信任惩罚(Over-trust Penalty)和回顾分配(Retrospection-Allocation)策略,几乎不增加额外成本。
- 通过观察自注意力矩阵中的知识聚合模式,OPERA识别出模型倾向于依赖少数摘要标记生成新标记,导致忽略图像标记并产生幻觉。
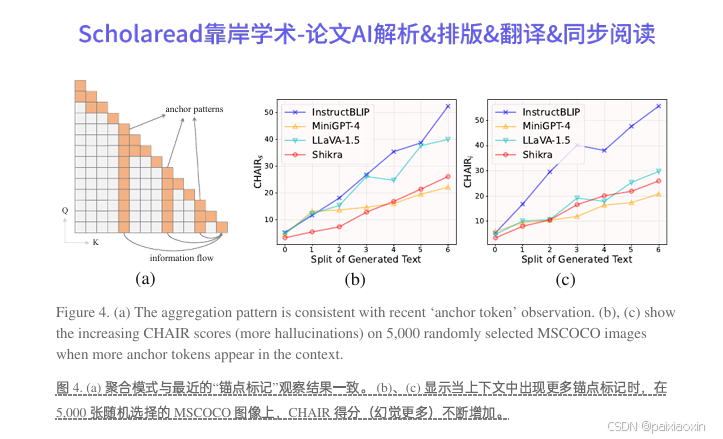
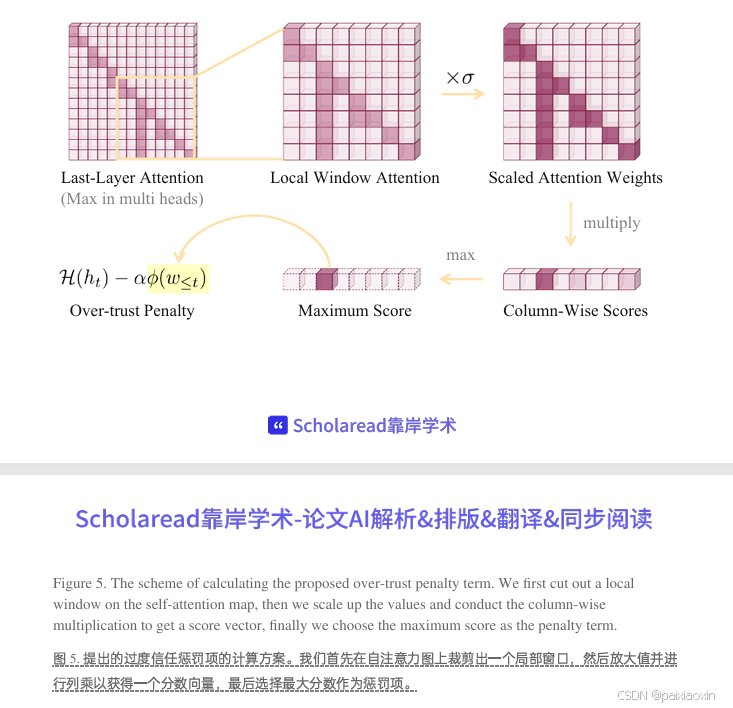
4.过度信任惩罚(Over-trust Penalty):
在beam-search解码过程中,对模型的对数几率(logits)引入惩罚项,以减轻过度信任问题。
5.回顾分配策略(Retrospection-Allocation):
当检测到知识聚合模式时,该策略允许解码过程回滚到摘要标记的位置,并重新分配标记选择。
6.实验结果:
通过在不同的MLLMs和指标上的广泛实验,OPERA显示出显著减轻幻觉的性能。
CV-MLLM必读论文合集:
希望这些论文能帮到你!如果觉得有用,记得点赞关注哦~ 后续还会更新更多论文合集!!
代码链接:
请注意,上述代码链接是示例性的,实际代码链接应在论文中提供。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)