DeepSeek-OCR 开源即霸榜,100token 干翻 7000 个,AI “JPEG 时刻” 降临!!
谁能想到,DeepSeek-OCR的模型竟让硅谷集体沸腾?DeepSeek刚开源的DeepSeek-OCR,凭"用视觉压缩一切文本"的颠覆性思路,不仅在GitHub狂揽4K星+、冲上榜HuggingFace热榜第二,更被网友盛赞"开源了谷歌Gemini的核心机密",堪称AI领域的"JPEG时刻"!DeepSeek的OCR项目由Haoran Wei、Yaofeng Sun、Yukun Li三位研究员
谁能想到,DeepSeek-OCR的模型竟让硅谷集体沸腾?DeepSeek刚开源的DeepSeek-OCR,凭"用视觉压缩一切文本"的颠覆性思路,不仅在GitHub狂揽4K星+、冲上榜HuggingFace热榜第二,更被网友盛赞"开源了谷歌Gemini的核心机密",堪称AI领域的"JPEG时刻"!
DeepSeek的OCR项目由Haoran Wei、Yaofeng Sun、Yukun Li三位研究员共同完成
-
Haoran Wei:曾就职于阶跃星辰,在2024年9月发表的论文中,身为论文一作的他所处单位为阶跃。他主导开发了旨在实现“第二代OCR”的GOT-OCR2.0系统,该项目在GitHub收获了超7800 star。目前他在DeepSeek主导OCR项目,DeepSeek-OCR的工作延续了GOT-OCR2.0的技术路径,致力于通过端到端模型解决复杂文档解析问题。

点击阅读原文,获取更多优质资源 -
Yaofeng Sun:从去年开始就陆续参与DeepSeek多款模型的研发,包括R1、V3等,在DeepSeek的模型研发工作中有着重要的参与和贡献。
-
Yukun Li(李宇琨):是一位谷歌学术论文近万引的研究员,他持续参与了包括DeepSeek V2、V3在内的多款模型的研发,在DeepSeek的模型研发领域有着丰富的经验和较高的学术影响力。
接下来让小编带大家解析一下DeepSeek-OCR模型~~

一图胜千言,解决大模型算力爆炸难题
大模型处理长文本时的算力焦虑,终于被DeepSeek找到破局之道——视觉即压缩。这一灵感源自最朴素的认知:一张图能承载海量文字,却只需更少token。就像人类扫一眼就能get核心信息,不必逐字阅读,DeepSeek-OCR将文本转化为视觉形式压缩存储,让模型"看图理解",从根源上降低计算开销。
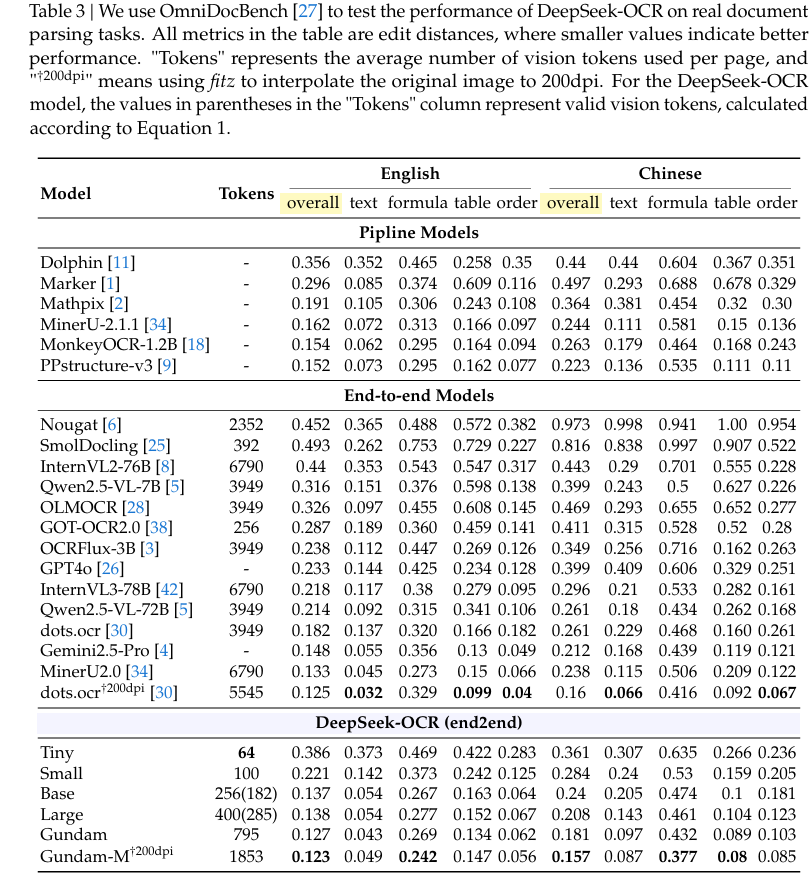
实测数据足以证明其强悍:
- 压缩率<10倍时(文本token数是视觉token数10倍内),OCR解码准确率高达97%;
- 即便压缩率拉满至20倍,准确率仍稳定在60%左右;
- 仅用100个视觉token,就超越了每页需256个token的GOT-OCR2.0;
- 不到800个视觉token,性能碾压需近7000个token的MinerU2.0。
更惊喜的是效率突破:单块A100-40G GPU每天能生成20万页优质LLM/VLM训练数据,20个节点集群单日可产出3300万页数据,彻底打通高效数据生产链路。
3.8亿参数量的"以小博大":两大核心组件揭秘
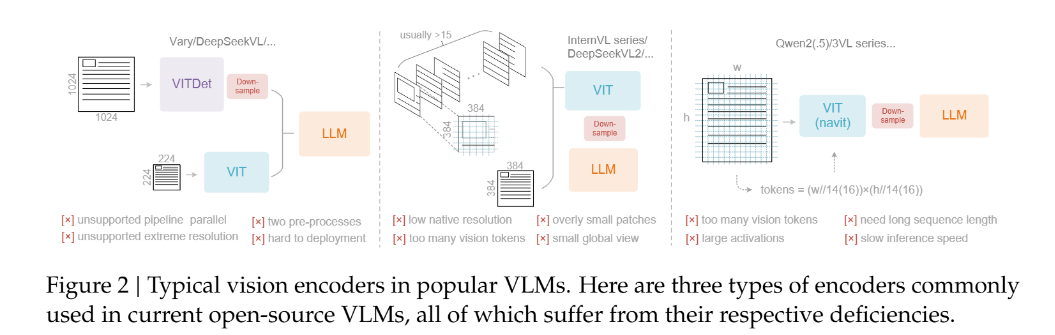
DeepSeek-OCR能实现"四两拨千斤",全靠创新架构支撑。这款3B规模的模型,核心由「DeepEncoder编码器」和「DeepSeek3B-MoE解码器」构成,大道至简却暗藏玄机。
🔍 编码器DeepEncoder:极致压缩的核心引擎
作为视觉压缩的关键,DeepEncoder(3.8亿参数)创造性地串联SAM-base与CLIP-large,用"局部处理→压缩→全局理解"的串行设计,实现高分辨率输入与低token输出的平衡:
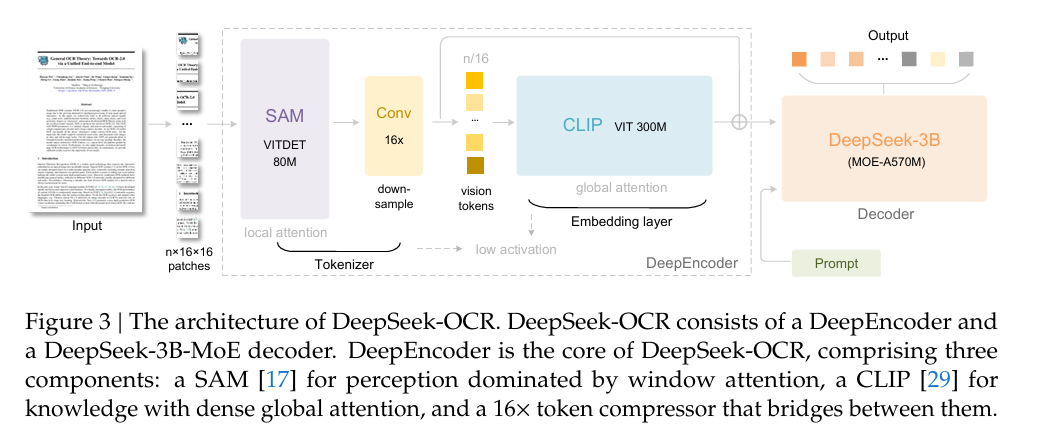
- 局部处理:800万参数的SAM-base通过窗口注意力,细粒度提取高分辨率图像特征,虽生成4096个token但内存可控;
- 16倍压缩:中间卷积模块大幅削减token数量,1024×1024图像经处理后仅余256个token;
- 全局理解:3亿参数的CLIP-large用全局注意力,深度解析浓缩后的少量token。
更灵活的是,它支持从"Tiny"(512×512,64token)到"Gundam"(动态分块,近800token)的多模式输入,可根据任务需求调整压缩强度,适配不同场景。
🧠 解码器DeepSeek3B-MoE:高效重建的智能大脑
解码器采用MoE架构,推理时仅激活6个路由专家+2个共享专家(共5.7亿激活参数),既保留3B模型的表达能力,又具备500M小模型的推理效率,能精准从压缩视觉token中重建原始文本。
不止于OCR:多场景突破+AGI新路径
这款被"命名耽误"的模型,早已超越传统OCR的边界:
- 复杂解析:轻松搞定金融报表、化学分子式、数学几何图,甚至自然图像;
- 多语言支持:覆盖近100种语言,适配全球各类PDF文档;
- 通用能力:兼具图像描述、物体检测等通用视觉理解能力。

更具想象力的是其对AI发展的启发:DeepSeek团队提出用光学压缩模拟人类遗忘机制——近期记忆用高分辨率图像+多token存储,远期记忆渐进缩放+少token压缩,为构建无限长上下文架构提供了新思路。正如卡帕西所言:“图像比文字更适合LLM输入,妙啊!” 这种统一视觉与语言的范式,被认为是通往AGI的重要探索。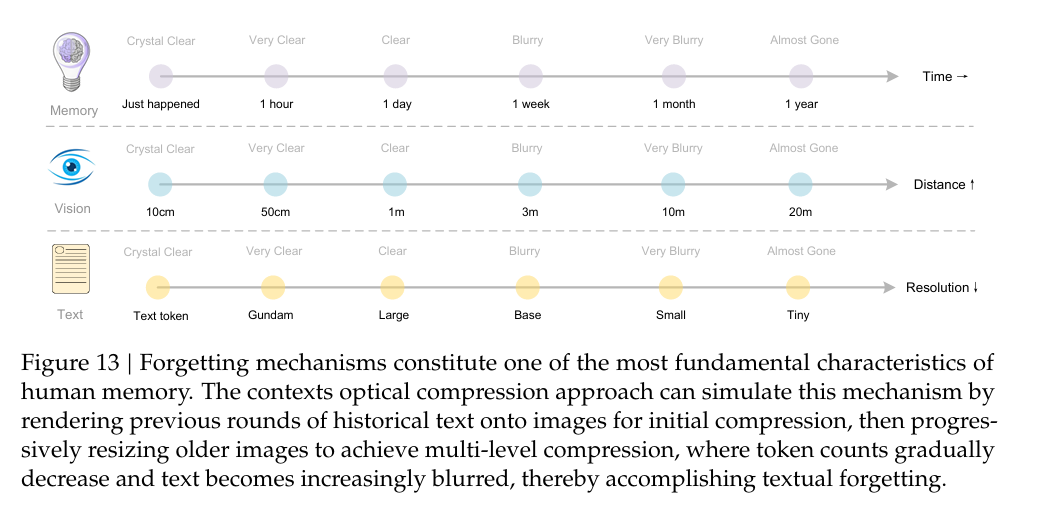
即刻体验开源黑科技
目前DeepSeek-OCR已完全开源,无论是学术研究还是工业应用,都能直接上手:
- GitHub:https://github.com/deepseek-ai/DeepSeek-OCR
- Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-OCR
DeepSeek-OCR快速上手指南
环境准备
DeepSeek-OCR运行环境要求为cuda11.8与torch2.6.0,具体部署步骤如下:
- 克隆仓库并进入项目目录
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
cd DeepSeek-OCR
- 创建并激活conda环境
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr
- 安装依赖包
- 首先下载vllm-0.8.5的whl文件
- 执行以下安装命令
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation
注:若需在同一环境中运行vLLM和transformers代码,无需担心"vllm 0.8.5+cu118 requires transformers>=4.51.1"之类的安装错误。
推理方式
vLLM推理
- 首先修改DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py中的INPUT_PATH、OUTPUT_PATH等设置
- 进入vllm推理目录
cd DeepSeek-OCR-master/DeepSeek-OCR-vllm
- 执行对应推理命令
- 图像流式输出
python run_dpsk_ocr_image.py
- PDF处理(A100-40G环境下并发约2500tokens/s)
python run_dpsk_ocr_pdf.py
- 基准测试批量评估
python run_dpsk_ocr_eval_batch.py
Transformers推理
- 代码调用示例
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR'
# 加载分词器与模型
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation='flash_attention_2',
trust_remote_code=True,
use_safetensors=True
)
model = model.eval().cuda().to(torch.bfloat16)
# 定义提示词、图像文件与输出路径
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'your_image.jpg'
output_path = 'your/output/dir'
# 执行推理
res = model.infer(
tokenizer,
prompt=prompt,
image_file=image_file,
output_path=output_path,
base_size=1024,
image_size=640,
crop_mode=True,
save_results=True,
test_compress=True
)
- 脚本运行方式
cd DeepSeek-OCR-master/DeepSeek-OCR-hf
python run_dpsk_ocr.py
支持模式
当前开源模型支持以下分辨率模式:
-
原生分辨率
- Tiny: 512×512(64个视觉token)
- Small: 640×640(100个视觉token)
- Base: 1024×1024(256个视觉token)
- Large: 1280×1280(400个视觉token)
-
动态分辨率
- Gundam: n×640×640 + 1×1024×1024
提示词示例
- 文档转换:
<image>\n<|grounding|>Convert the document to markdown. - 图像OCR:
<image>\n<|grounding|>OCR this image. - 无格式OCR:
<image>\nFree OCR. - 图表解析:
<image>\nParse the figure. - 图像描述:
<image>\nDescribe this image in detail. - 定位任务:
<image>\nLocate <|ref|>xxxx<|/ref|> in the image. - 中文示例:
<image>\n识别"先天下之忧而忧"在图中的位置。
从100个token颠覆行业认知,到用视觉压缩重构AI记忆逻辑,DeepSeek-OCR不仅解决了长文本处理的算力痛点,更打开了多模态融合的新可能。这场AI的"光学压缩革命",你准备好参与了吗?


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)