大语言模型评估测试
CMMLU和C-Eval是两个中文多学科评估基准。CMMLU包含67个主题的测试数据,主要评估中文大模型的知识和推理能力,项目结构分为src、data、script三个模块。C-Eval涵盖52个学科的13948道题目,分为4个难度等级,核心评估代码位于code/evaluator_series目录下,提供命令行参数评估功能。两个项目均开源在GitHub平台,为中文大语言模型评估提供标准化测试框架
文章目录
一、CMMLU
CMMLU全称Chinese Multi-choice Multi-subject Understanding,是一个中文多选多学科理解评估基准,用于评测大语言模型在中文语境下的知识和推理能力。
其中包含艺术、商业、文化、法律、大学、高中等67个主题。
该项目主要包含3个文件。src、data、script三个文件夹.
src:主要包含调用模型测试的py代码。data:data文件夹下包含dev和test两个子文件夹。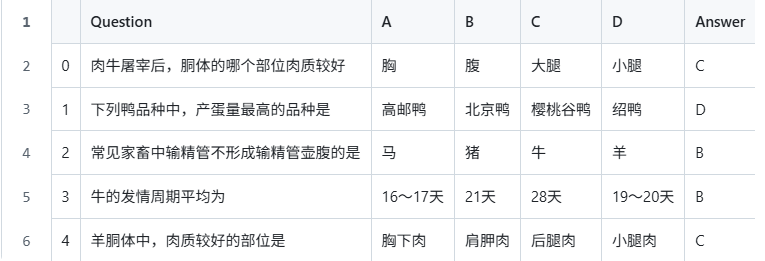

script:封装了一层shell脚本,调用script中的py文件。
仓库链接:CMMLU
二、C-Eval
C-Eval涵盖52个不同学科的13948个多项选择题,这些题目被分为4个不同的难度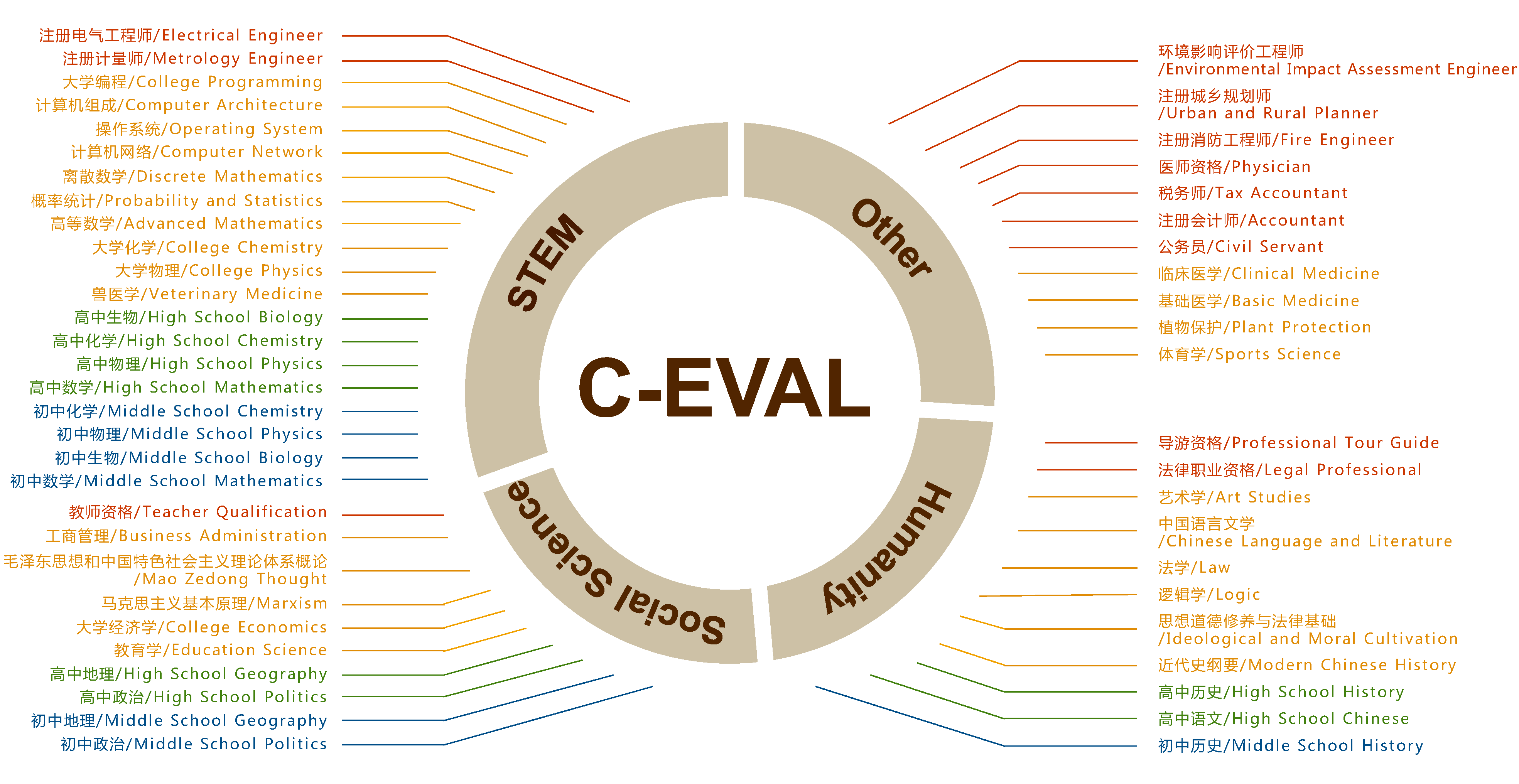
该项目下主要内容在code/evaluator_series目录下。
其中evaluators文件夹下是对各个具体模型评估函数的实现。
而eval.py和eval_llama.py则是进行了一层封装,便于在命令行输入参数运行评估的脚本。
仓库链接:ceval模型评估脚本
数据集链接:ceval数据集
三、gsm8k数据集
全称Grade School Math 8k,是一个包含8k个小学数学题的英文数据集,解题步骤一般需要2-8步推理过程。
主要评测模型的数学推理能力。
数据格式以QA对的形式出现,同时问题以自然语言的形式描述,而非数学公式。
数据集链接:gsm8k

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)