Timbr GraphRAG:结构化与非结构化数据,驱动更聪明的企业级GenAI
GraphRAG(基于知识图谱的检索增强生成)是传统RAG方法的新进化,它结合了图谱驱动的结构化数据检索与基于向量的非结构化文本检索能力。传统RAG主要通过文本向量相似性检索文档片段,这对一般场景有效,但在面对需要推理、跨表连接等复杂问题时往往力不从心,经常“无法连点成线”,也难以把握大文档的全局语义。GraphRAG通过整合知识图谱,显式标注实体与事实间的业务关系,使AI能够像专家一样沿数据逻辑
摘要
Timbr GraphRAG SDK通过知识图谱创新,融合结构化SQL数据与非结构化文本,为大模型带来高准确率、可解释性的AI检索增强生成(RAG),适合企业与科研的智能决策,无需额外搭建图数据库,助力业务创新与数据价值释放。
引言
Timbr GraphRAG SDK将知识图谱的智能推理能力引入检索增强生成(RAG)领域,使大语言模型(LLM)能够同时检索并推理结构化与非结构化企业数据,为企业用户和开发者带来更准确、上下文敏感的智能问答体验。Timbr平台通过本体(Ontology)语义层,将企业分散的数据虚拟成为一个可被SQL查询的知识图谱,大大提升了数据访问与分析的便捷性,赋能AI驱动的业务决策。
什么是GraphRAG及其重要意义
GraphRAG(基于知识图谱的检索增强生成)是传统RAG方法的新进化,它结合了图谱驱动的结构化数据检索与基于向量的非结构化文本检索能力。传统RAG主要通过文本向量相似性检索文档片段,这对一般场景有效,但在面对需要推理、跨表连接等复杂问题时往往力不从心,经常“无法连点成线”,也难以把握大文档的全局语义。
GraphRAG通过整合知识图谱,显式标注实体与事实间的业务关系,使AI能够像专家一样沿数据逻辑链推理,从而获得更精确、业务语境贴合的答案。该方法不仅可依赖图数据库或本体层中的结构化信息,还能结合文本检索,输出涵盖数据库事实与文档上下文的答案,极大提升了大模型的准确率、解释性与业务契合度。
GraphRAG典型应用场景
GraphRAG在关键知识横跨结构化和非结构化数据的各种场合尤为重要,能够解锁文本AI难以覆盖的洞察:
客户支持:将结构化的客户档案、交易记录与非结构化的工单、知识库相结合,实现更完善、个性化的智能客服。
金融与医疗:能自动整合业务数据库中的核心数据与政策文档、学术论文,有效支持金融风控、临床决策等高要求场景。
IT运维:融合系统配置、业务表与日志、技术文档,实现自动定位异常、精准推荐解决方案,推进智能化运维。
企业分析:报表、结构化分析结果和会议纪要、业务报告等文档深度贯通,加速多维决策与洞察。
Timbr GraphRAG的独特能力与价值
1. 本体驱动的智能知识图谱(Ontology-Driven Knowledge Graph)
Timbr允许用户在现有SQL数据源基础上,低成本快速构建企业专属知识图谱,无需复杂ETL流程或额外图数据库。企业只需定义本体(Ontology),即刻让业务实体、指标、层级在知识图谱中自动联通,保障数据一致性和实时性。
2. 一体化结构化与非结构化智能检索
Timbr GraphRAG SDK可智能路由用户问题:结构化查询(如“按地区统计总销售额”)由本体编译成SQL直查数据仓库,非结构化查询(如“客户对产品X的反馈有哪些?”)则自动走向量检索。对于需要结合多数据源的混合性问题,GraphRAG自动融合结构化结果与文档片段,一次性输出全面解答。
3. 业务语义精确可解释
本体层深度嵌入企业专属的业务定义、指标和层级,让AI能够精准理解“高价值客户”“Q1毛利率”这类专业名词,大大降低大模型幻觉和语义误读风险,确保答案真实可信。
4. 提速开发与敏捷扩展,原生兼容云数仓
Timbr GraphRAG 建立在SQL与主流云数据仓库之上(如Snowflake、BigQuery、Databricks等),开发者可直接用熟悉的SQL构建图谱。SDK内置参考应用、Streamlit UI和逐步文档,助力企业与数据团队敏捷部署图谱RAG系统,无需新学图数据建模技能,所有数据安全“留在内部”统一治理。
独特能力与传统方案对比
|
维度 |
传统DIY GraphRAG |
Timbr GraphRAG SDK |
|---|---|---|
| 知识图谱搭建 |
需迁移数据至新图数据库或手工编写本体,复杂且需专家 |
快速将关系型数据库自动虚拟为知识图谱,本体定义简单、高效 |
| 数据整合 |
跨源融合难,需手工ETL和拼接多服务,结构化与文本分离 |
虚拟整合多源数据,统一由本体与SQL访问,结构化与文本自然协同 |
| 结构化查询 |
仅依赖向量或简单模版,结构化事实不准确亦易陈旧 |
直接通过SQL和真实关系获取最新数据,复杂关联由本体自动管理 |
| 非结构化检索 |
需自建向量库和自定义聚合流程,融合复杂 |
SDK原生融合,自动将结构化和文本查询结果合并输出 |
| 准确率与上下文 |
容易丢失关系,人工图谱与数据易不同步,难保证业务一致性 |
本体持续同步数据、关系,答案更透明、精准、实时 |
| 开发维护成本 |
各模块分散,需拼接和单独维护,升级慢 |
一体化SDK,企业只需专注定义本体和配置,所有数据流流程自动化 |
Timbr GraphRAG SDK工作原理与实际案例
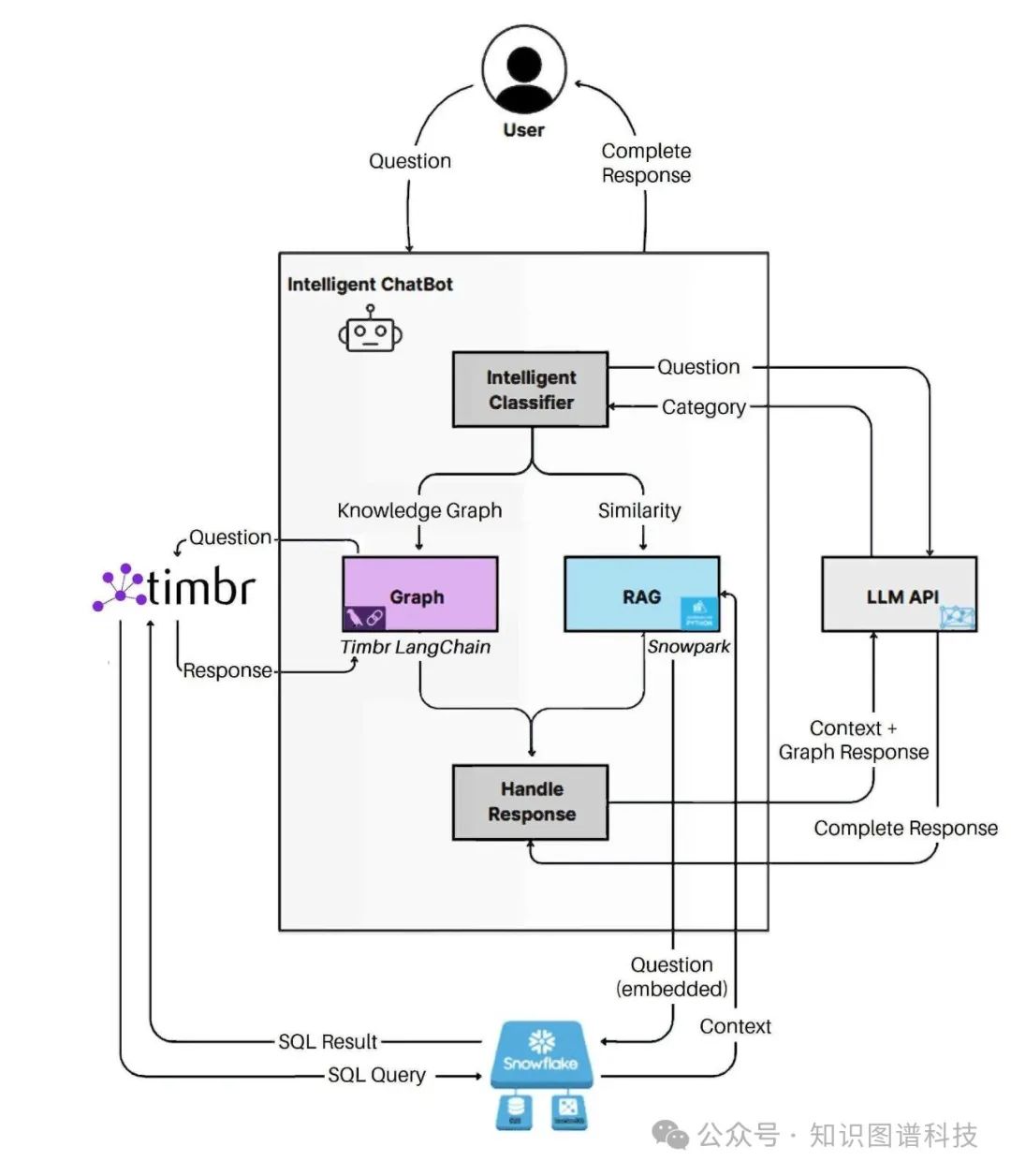
典型工作流程
- 用户提问
- 问题自动识别
(SDK判别结构化/非结构化/混合型)
- 结构化路径
:通过Timbr本体翻译成SQL,查询原始数据,输出准确事实
- 非结构化路径
:通过向量检索技术,从文档/评论中定位最相关文本片段
- 答案智能聚合
:结构化数据和文本证据统一输入大模型生成最终答案
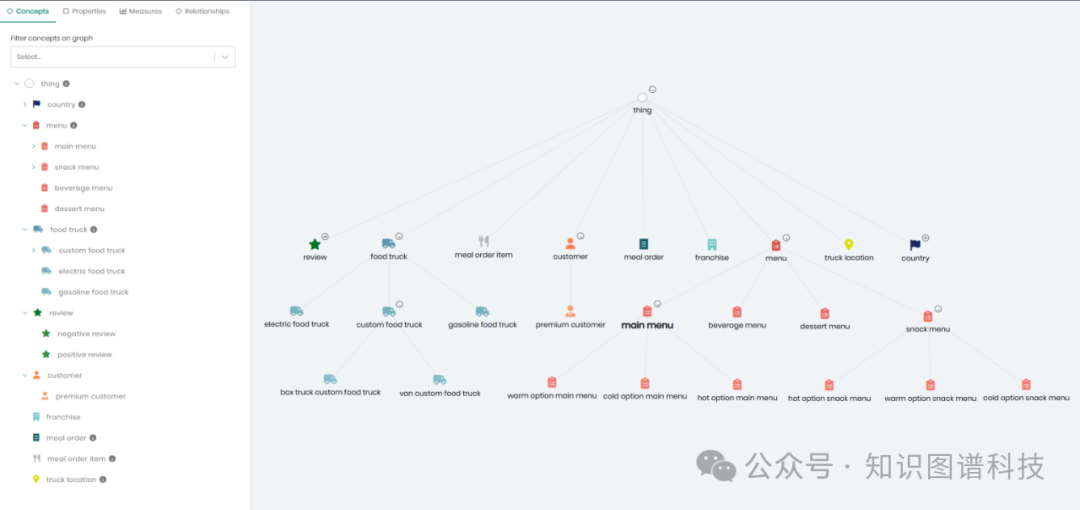
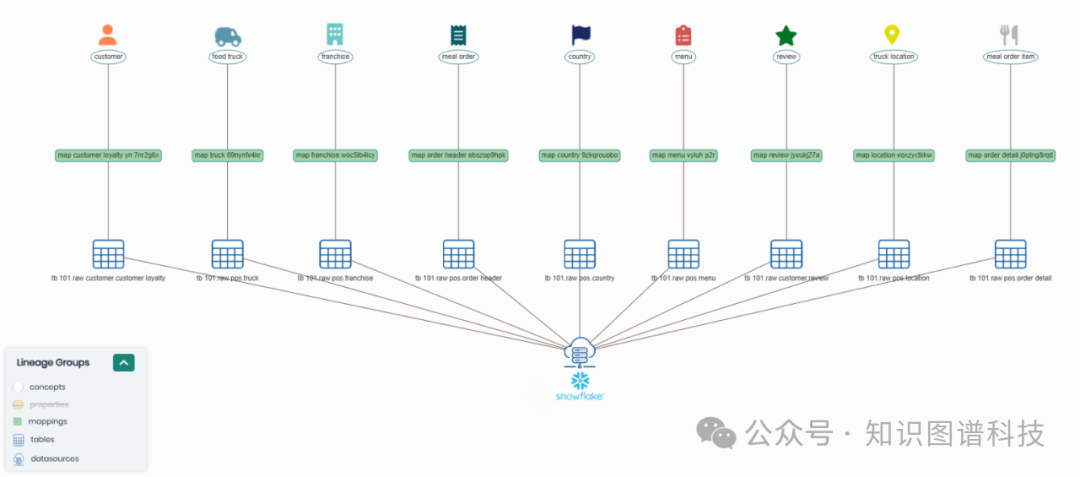
场景应用实例 — 食品卡车数据集(Snowflake Tasty Bytes)
数据结构:
关系表:食品卡车、客户、订单等标准表结构
文本数据:客户评论(PDF等格式,已向量化)
使用流程:
-
用户用自然语言提问,“哪个食品卡车鸡肉评价最好?客户怎么说?”
-
SDK自动路由检索路径:
-
结构化部分:查找鸡肉菜品得分最高的卡车及相关订单明细
-
非结构化部分:从评论PDF中检索提及鸡肉的客观评价片段
-
-
合成最终答案,例如:“Bella’s Best Bites餐车2022年鸡肉销售最佳,客户高度评价其‘鲜嫩鸡肉’和‘调味酱鲜美’。”
总结与前景展望
Timbr GraphRAG让AI问答像企业专家一样准确、透明、可追溯,将结构化事实与非结构化洞察相结合,极大释放企业数据的价值。通过本体语义层的引擎,无需额外图数据库或复杂迁移,便捷地实现从数据到洞察、从查询到推理的转变。未来,Timbr GraphRAG将在企业知识管理、智能决策和生成式AI应用场景持续引领创新。
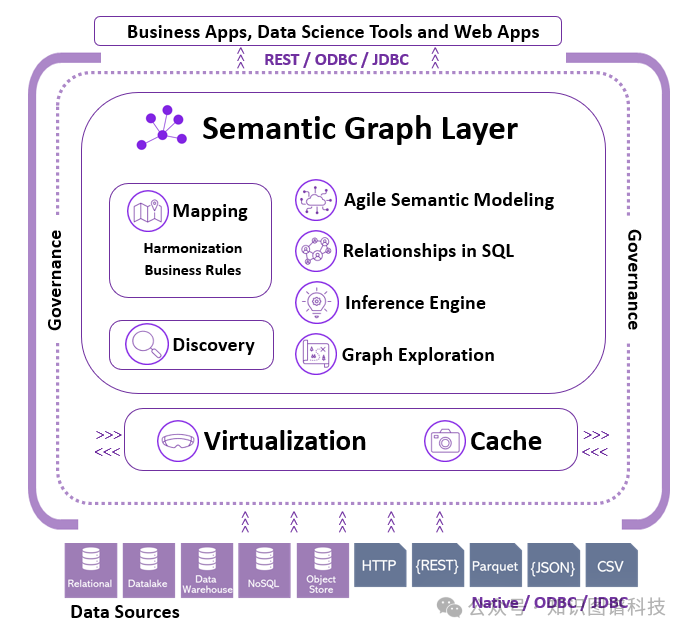
Timbr概述
Timbr 为 SQL 数据生态系统引入知识图谱能力,通过在现有数据库之上搭建虚拟语义模型,实现数据的语义化访问与分析。Timbr 不存储数据,而是作为连接现有数据源的虚拟层,确保数据保留在原处,支持主流 BI 及数据科学工具无缝集成 。
主要功能
- 语义图模型构建
:可基于数据库构建具备数据含义、协调与关系的语义图模型,实现数据源与业务概念的高效映射 。
- 虚拟化与高性能
:支持数据的虚拟化和缓存,在保障数据安全的前提下提升查询效率 。
- 多语言查询支持
:模型可通过 SQL 以及 Spark、Python、R、Java、Scala 进行查询,助力数据科学与机器学习 。
- 数据可视化与高级分析
:可将数据关系可视化为网络图,并使用图算法进行高级分析 。
- 通用接口
:支持 REST、ODBC、JDBC 等通用接口,兼容各类 Web 应用和分析工具 。
- 模型和本体导入
:可导入行业数据模型、ERD、OWL 本体等,快速生成 SQL 本体(语义图模型) 。
- 语义推理与图遍历
:为大数据和 SQL 系统提供原生的本体推理和图遍历能力,弥合 SQL 和现代知识图谱之间的鸿沟 。
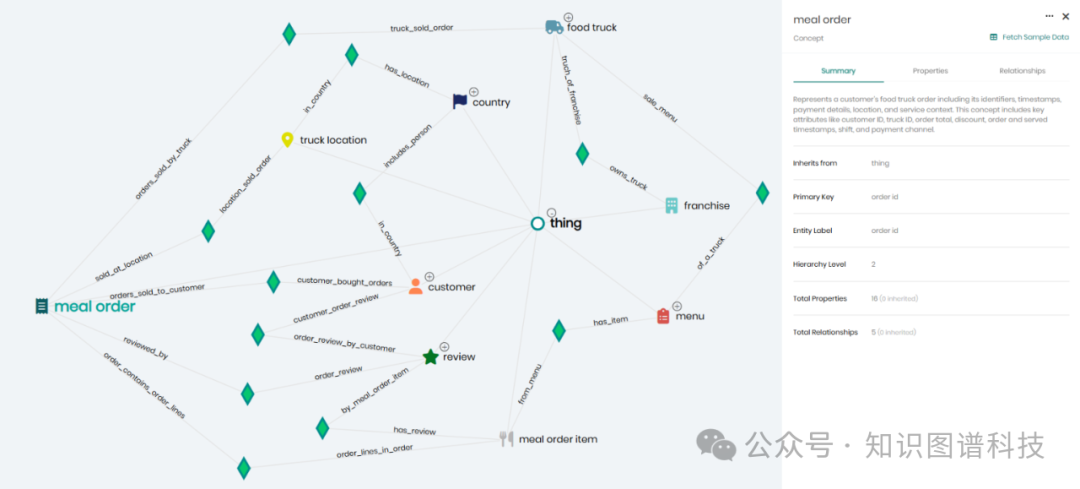
本体与语义建模
- 本体定义
:为组织内信息共享定义统一词汇表,包括机器可解释的核心概念与关系 。
- 结构特征
:本体采用图结构,每个节点表示一个概念(如人、地点、客户、产品等),用于对分布式数据赋予通用业务含义 。
- 数据访问
:可通过直观界面或标准 SQL 建模和探索本体,SQL 用户可通过 JDBC/ODBC 访问虚拟模式中的虚拟表(概念) 。
组成要素
- 概念
:映射到 OWL 类,作为虚拟表在 SQL 中公开 。
- 属性
:映射到 OWL 数据类型属性,对应虚拟表的列 。
- 关系
:映射到 OWL 对象属性,通过 SQL 外键在图模式中展现 。
- 映射与视图
:物理表通过映射关联到本体,视图可用于构建聚合概念(立方体)或特定的非规范化视图 。
应用价值
Timbr 提供敏捷的语义建模能力,支持不同来源数据的统一理解、发现和访问;通过虚拟化和兼容性支持现代数据分析、AI 和业务智能场景 。
如何学习AI大模型 ?
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
(👆👆👆安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
(👆👆👆安全链接,放心点击)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献93条内容
已为社区贡献93条内容

所有评论(0)