【AI论文】Fast-dLLM v2:高效块扩散式大型语言模型(LLM)
摘要:本研究提出Fast-dLLMv2,一种创新的块扩散语言模型,通过将预训练AR模型高效适配为并行生成架构,仅需10亿token微调数据(较现有方法减少500倍)。模型采用分层注意力掩码实现块级双向建模,配合分层缓存机制(块级/子块缓存),在保持AR模型质量的同时实现2.5倍解码加速。实验表明其性能与AR基线相当,为高效LLM部署提供了新方案。论文代码将开源(Huggingface链接:Pape
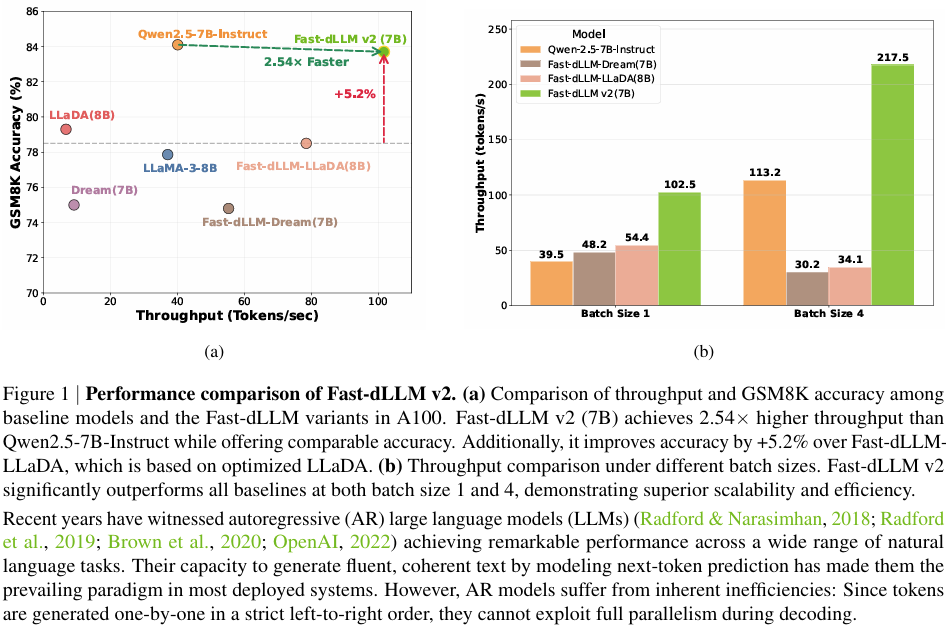
摘要:自回归(Autoregressive, AR)大型语言模型(LLMs)在广泛的自然语言任务中取得了显著成效,但其固有的顺序解码方式限制了推理效率。本研究提出Fast-dLLM v2——一款精心设计的块扩散式语言模型(block diffusion language model, dLLM),它通过将预训练的AR模型高效适配为dLLM,实现并行文本生成,且仅需约10亿token的微调数据。与全注意力扩散式大型语言模型(如Dream需5800亿token)相比,其训练数据量减少了500倍,同时保持了原始模型的性能。该方法引入了一种新颖的训练方案,将块扩散机制与互补注意力掩码相结合,在不影响AR训练目标的前提下,实现了块级别的双向上下文建模。为进一步加速解码,我们设计了分层缓存机制:块级缓存用于存储跨块的历史上下文表示,子块缓存则支持在部分解码的块内实现高效并行生成。结合并行解码流程,Fast-dLLM v2在保持生成质量的同时,实现了较标准AR解码最高达2.5倍的加速。在多样化基准测试中的广泛实验表明,Fast-dLLM v2在准确性上与AR基线相当或更优,同时在dLLM中达到了顶尖的效率水平——这为快速且精准的大型语言模型的实际部署迈出了重要一步。代码与模型将公开发布。Huggingface链接:Paper page,论文链接:2509.26328
研究背景和目的
研究背景:
近年来,自回归(AR)大型语言模型(LLMs)在自然语言处理任务中取得了显著进展,其通过逐个生成token的方式实现了流畅且连贯的文本生成。
然而,AR模型的固有顺序解码机制限制了其推理效率,尤其是在需要生成长文本或处理复杂推理任务时,解码速度成为瓶颈。为了解决这一问题,扩散语言模型(dLLMs)作为一种替代方案逐渐受到关注。dLLMs通过允许同时预测或优化多个token(甚至整个token块),理论上可以实现更高的解码并行性,从而提高生成效率。
然而,现有的dLLMs在实践中的应用仍面临诸多挑战。
首先,许多dLLMs需要固定的序列长度或对生成长度有严格限制,缺乏灵活性。其次,由于双向注意力机制的使用,dLLMs往往无法有效利用KV缓存,导致推理延迟超过AR模型。此外,许多dLLMs需要大量训练数据(如数百亿token)来实现与AR模型相当的性能,这增加了训练成本和时间。
研究目的:
本研究旨在提出一种高效的块扩散语言模型(Fast-dLLM v2),以解决现有dLLMs在并行文本生成中的效率问题。
具体目标包括:
- 减少训练数据需求:通过开发一种后训练策略,将预训练的AR模型适应到块扩散框架中,仅需约10亿token的微调数据,实现与全注意力扩散模型相当的损失less适应,同时保持原始模型的预测性能。
- 提高推理效率:设计一种分层级注意力掩码结构,实现块级双向上下文建模,同时保留AR训练目标。
- 提升并行解码速度:通过分层缓存和子块缓存机制,加速块内未完全解码时的块内生成和块内解码。
- 保持生成质量:在不过降低生成质量的前提下,实现与AR基线相当的推理能力。
研究方法
1. 数据集构建:
通过收集和整理超过60K的高质量step-level标注数据,构建高质量的监督实例。。
2. 模型训练:
采用SFT(监督微调)和RL(基于强化学习的奖励塑造)相结合的双阶段训练范式。。
- 监督微调(SFT):在训练过程中定期评估模型性能,根据验证集和RL训练的效果,对不满意表现进行适当调整。。。。。。。。。。。。。。。
未来研究方向
1. 跨模态数据训练:
探索更多高效的数据集构建方法,减少对外部工具的依赖,提高模型在处理长距离表格数据时的准确性。。。
2. 增强模型的泛化能力:
持续研究如何提升TATTOO的泛化能力,使其能够更有效地处理更复杂的表格推理任务,并在验证过程中保持高精度和可靠性。
3. 用户友好型界面与交互:
设计一个直观且易于使用的用户界面,减少用户的学习成本,提高系统的可用性和可访问性。
4. 持续优化与扩展:
持续优化TATTOO模型,通过引入更先进的注意力机制,进一步提升模型在处理复杂情况时的泛化能力。
5. 实际应用与部署:
将TATTOO模型应用于实际医疗场景,如远程医疗、健康管理和患者教育等,验证其在实际应用中的有效性和可行性。
6. 未来研究方向:
- 多模态数据集:探索整合多模态数据(如文本、图像和表格数据)以提升模型的泛化能力。
- 实时验证与反馈:开发实时验证系统,确保模型在处理复杂情况时的准确性和可靠性。
- 个性化医疗:利用TATTOO模型根据患者的具体需求提供个性化医疗建议,提高治疗效果。
- 跨领域合作:与医疗科技公司合作,共同开发更先进的医疗辅助工具。
通过上述方法和未来研究方向,本研究旨在推动TATTOO模型在表格推理任务中的广泛应用,并探索其在其他复杂推理任务中的潜力,同时关注其在实际医疗场景中的应用和验证。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)