TPAMI 2025 | 大模型导航新突破!NavCoT用三步推理链实现视觉语言导航性能跃升
上图展示了NavCoT的完整工作流程:首先通过视觉到文本系统将环境图像转换为文字描述,然后LLM基于指令、历史轨迹和当前观察,依次完成未来想象、视觉信息过滤和行动预测三个步骤,形成可解释的推理链。在R2R数据集上,基于LLaMA 2的NavCoT通过简单微调,在成功率(SR)和路径长度加权成功率(SPL)上比基于GPT-4的方法提升约7个百分点,同时单步推理时间从9.8秒缩短至0.5秒。实验表明,
点击下方“大模型与具身智能”,关注我们
在具身智能领域,让AI智能体像人类一样看懂环境、听懂指令并自主导航,一直是研究者追求的重要目标。视觉语言导航(VLN)任务要求智能体依据自然语言指令在复杂3D环境中完成导航,这一任务既考验模型的视觉理解能力,又依赖精准的语言推理能力。近期,一篇发表于TPAMI 2025的研究论文《NavCoT: Boosting LLM-Based Vision-and-Language Navigation via Learning Disentangled Reasoning》提出了创新性的"导航思维链"策略,为解决这一难题提供了全新思路。
现有方法的困境:大模型也会"迷路"
尽管大语言模型(LLMs)凭借强大的常识推理能力在VLN任务中展现出潜力,但现有方法存在两大核心问题:
-
领域差距显著:通用LLM的训练语料与导航任务的实际场景脱节,导致模型难以适应物理世界的交互逻辑
-
决策过程黑箱化:直接让LLM预测导航行动,缺乏中间推理步骤,既降低了可解释性,也难以保证决策准确性
传统方法要么依赖GPT-4等闭源大模型导致成本高昂,要么直接让模型输出行动指令,忽略了人类导航时"想象-验证-决策"的认知过程。
核心创新:NavCoT导航思维链的三重推理机制
论文提出的NavCoT(导航思维链)策略创新性地将LLM重塑为兼具世界模型和推理能力的导航智能体,其核心在于将导航决策分解为三个解耦的推理步骤:
1. 未来想象(FI):构建心理预期
受人类导航时会预先设想前方场景的启发,NavCoT让模型在每个决策步先生成对下一观察的想象(如"敞开的门"、"楼梯"等)。这些想象并非凭空产生,而是严格基于指令中提到的对象或场景,确保推理始终围绕任务目标展开。
2. 视觉信息过滤(VIF):匹配预期与现实
在生成想象后,模型需要从当前观察到的多个候选视图中,筛选出与想象最匹配的选项。这一步骤有效解决了视觉信息冗余的问题,帮助模型聚焦关键线索。
3. 行动预测(AP):基于推理做决策
结合前两步的推理结果,模型最终做出行动选择。通过这种分步推理,原本复杂的导航决策被显著简化。
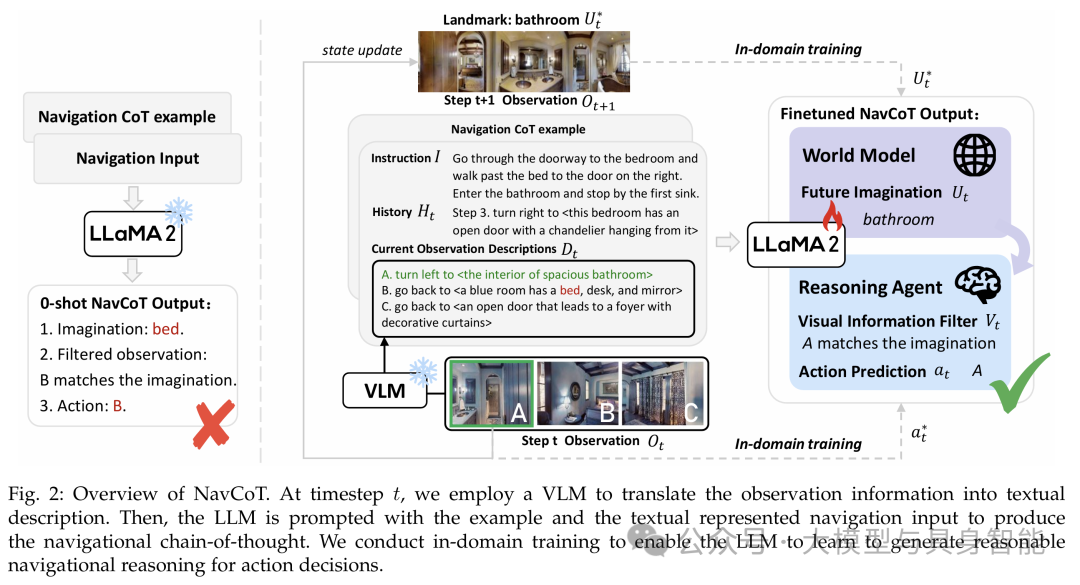
上图展示了NavCoT的完整工作流程:首先通过视觉到文本系统将环境图像转换为文字描述,然后LLM基于指令、历史轨迹和当前观察,依次完成未来想象、视觉信息过滤和行动预测三个步骤,形成可解释的推理链。
关键技术:让大模型学会导航的训练策略
为了让LLM高效掌握导航推理能力,研究团队设计了针对性的训练方案:
1. 真值推理数据构建
通过LLM从指令中提取关键地标,并利用CLIP模型计算图像与地标相似度,自动生成高质量的推理标签。例如在R2R数据集中,这种方法的地标提取准确率可达100%,为训练提供了坚实基础。
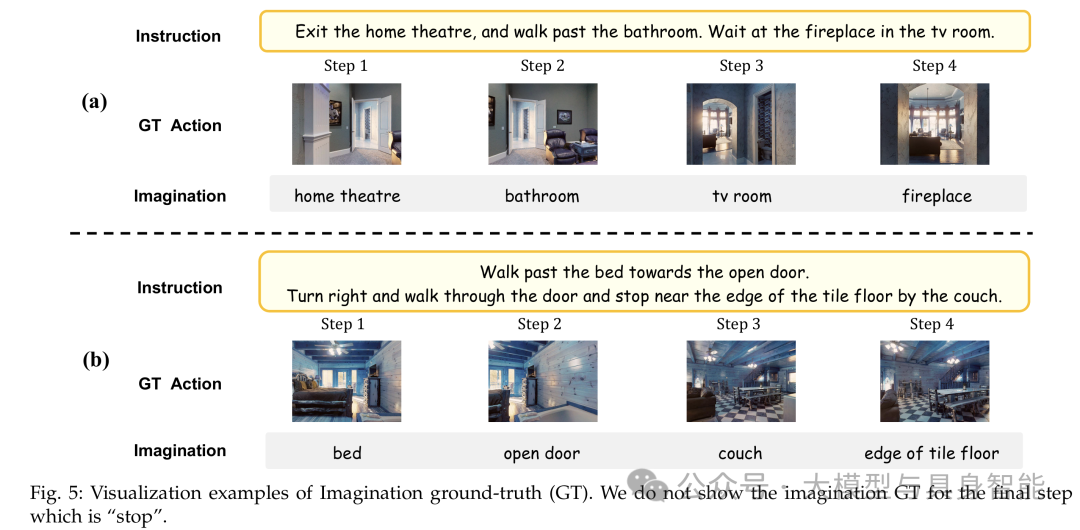
上图展示了模型生成的想象真值示例,即使地标在图像中占比很小(如图中步骤2的"水槽"),系统仍能准确识别并生成对应的想象描述。
2. 多任务预训练+微调
-
预训练阶段:将三个推理步骤拆分为独立任务,分别训练模型的想象能力、过滤能力和决策能力
-
微调阶段:整合三个步骤,训练模型生成完整的导航思维链
这种训练方式仅需调整少量参数(120万-160万可训练参数),单个V100 GPU即可支持,大幅降低了部署成本。
实验验证:性能全面超越现有方法
研究团队在四个主流VLN数据集(R2R、RxR、REVERIE、R4R)上进行了全面评估,结果显示NavCoT表现出显著优势:
1. 对比GPT-4方法
在R2R数据集上,基于LLaMA 2的NavCoT通过简单微调,在成功率(SR)和路径长度加权成功率(SPL)上比基于GPT-4的方法提升约7个百分点,同时单步推理时间从9.8秒缩短至0.5秒。
2. 消融实验验证各组件有效性
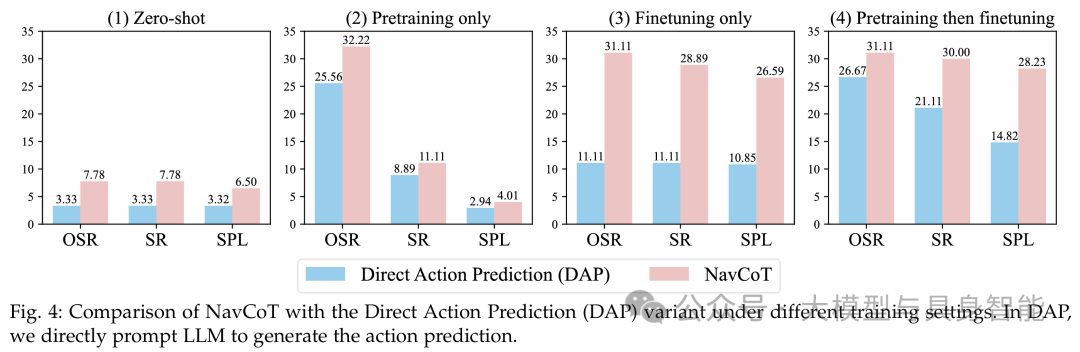
实验表明,完整的三步骤推理(FI+VIF+AP)在所有指标上均优于直接行动预测(DAP),证明解耦推理的必要性。领域内训练相比零样本推理有显著提升,其中微调对导航成功率的提升最为明显。
3. 特殊场景泛化能力

NavCoT在指令地标少、连续步骤指向同一目标等特殊情况下仍能保持稳健性能,显示出其对复杂导航场景的适应性。
方法对比:为什么NavCoT更懂导航?

与传统思维链方法相比,NavCoT的优势体现在:
-
推理更聚焦:结构化的三步推理减少冗余信息,避免思维发散
-
决策更透明:每个步骤的输出均可解释,便于追溯决策逻辑
-
学习更高效:通过形式化标签和领域内训练,小模型也能超越大模型
结语:迈向可解释的具身智能
NavCoT通过解耦推理和高效训练,为基于LLM的视觉语言导航提供了新范式。其创新点不仅在于提升了导航性能,更重要的是模仿人类导航认知过程,使AI的决策过程变得可解释、可干预。未来将NavCoT与大型视觉语言模型结合,有望进一步突破视觉信息损失的限制,推动具身智能在真实世界机器人应用中的落地。
论文信息
题目:NavCoT: Boosting LLM-Based Vision-and-Language Navigation via Learning Disentangled Reasoning
作者:Bingqian Lin, Yunshuang Nie, Ziming Wei, Jiaqi Chen, Shikui Ma, Jianhua Han, Hang Xu, Xiaojun Chang, Xiaodan Liang
源码:https://github.com/expectorlin/NavCoT

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)