NeurIPS 2025 | 华中科大等提出NAUTILUS:首个大规模水下多模态模型,破解深海“看图说话”难题
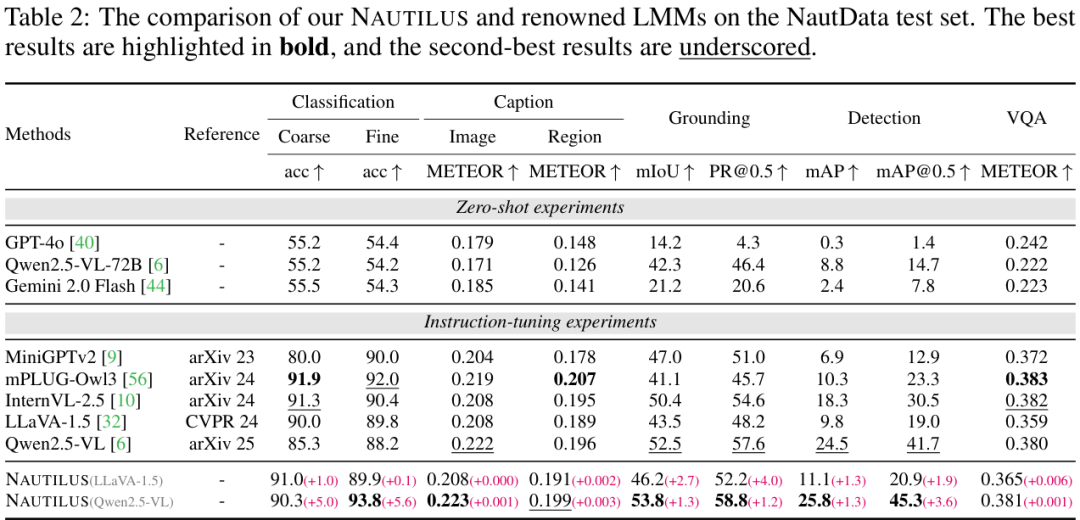
在NautData测试集上,集成了VFE模块的NAUTILUS(以Qwen2.5-VL为基础)在全部八项任务上,性能相比原始的Qwen2.5-VL都有了一致性的提升,并在大多数任务上超越了包括LLaVA-1.5在内的其他基线模型。这个VFE模块是一个即插即用的组件,它的设计思想借鉴了水下成像的物理先验知识。总的来说,NAUTILUS这项工作通过“构建大规模专属数据集”和“设计基于物理先验的即插即用
大家好,今天想和大家聊一篇非常“深”的研究。我们都知道,多模态大模型在理解我们日常生活的世界方面已经非常强大了,但如果把它们扔进深海,情况会怎么样?由于水下环境独特的图像退化问题——比如光线吸收、散射导致的颜色失真和对比度下降——大多数模型都会“水下不服”。
最近,来自华中科技大学和国防科技大学的研究者们,针对这个难题提出了一个名为 NAUTILUS 的大型多模态模型,专门用于水下场景的理解。这个名字致敬了《海底两万里》中的“鹦鹉螺号”,寓意着对深海世界的探索,可以说是非常贴切了。这项工作已经被 NeurIPS 2025 接收。
一起来看看他们是如何让AI“深潜”的。

-
论文标题: NAUTILUS: A Large Multimodal Model for Underwater Scene Understanding
-
作者: Wei Xu, Cheng Wang, Dingkang Liang, Zongchuang Zhao, Xingyu Jiang, Peng Zhang, Xiang Bai
-
机构: 华中科技大学, 国防科技大学
-
论文地址: https://arxiv.org/abs/2510.27481
-
项目地址: https://github.com/H-EmbodVis/NAUTILUS
“数据”+“算法”双管齐下
面对水下视觉这个硬骨头,研究者们认为问题的根源主要有两个:一是缺乏大规模、高质量、多任务的标注数据用于模型训练;二是在算法层面,现有模型没有专门针对水下图像退化问题进行优化。
因此,他们的解决方案也是双管齐下:构建一个全新的水下数据集 NautData,并设计一个即插即用的 视觉特征增强(Vision Feature Enhancement, VFE) 模块。
NautData:首个大规模水下多任务指令微调数据集
正所谓“兵马未动,粮草先行”,一个好的数据集是成功的一半。为了解决水下多模态研究的数据荒,团队构建了 NautData。
这是一个包含 145万个图像-文本对 的大规模数据集,全面支持 八种不同的水下场景理解任务,覆盖了从粗粒度的场景分类到细粒度的物体检测和描述等多个层次。
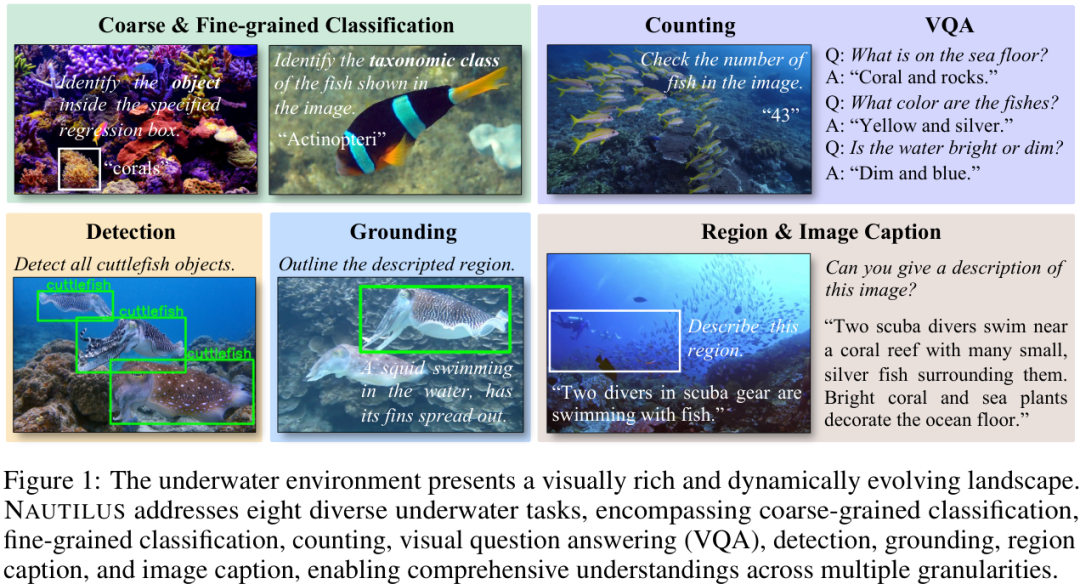
这八项任务包括:
-
粗粒度分类 (Coarse-grained classification)
-
细粒度分类 (Fine-grained classification)
-
计数 (Counting)
-
视觉问答 (VQA)
-
检测 (Detection)
-
指代定位 (Grounding)
-
区域描述 (Region caption)
-
图像描述 (Image caption)
相比于现有的水下视觉语言数据集,NautData在任务多样性和数据规模上都实现了碾压,为训练和评估强大的水下多模态模型提供了坚实的基础。

NAUTILUS模型与VFE模块
有了数据,接下来就是模型设计。NAUTILUS的整体框架是基于现有成熟的大型多模态模型(LMMs),如LLaVA-1.5和Qwen2.5-VL,其核心创新在于引入了一个专门应对水下图像降质的 视觉特征增强(VFE)模块。
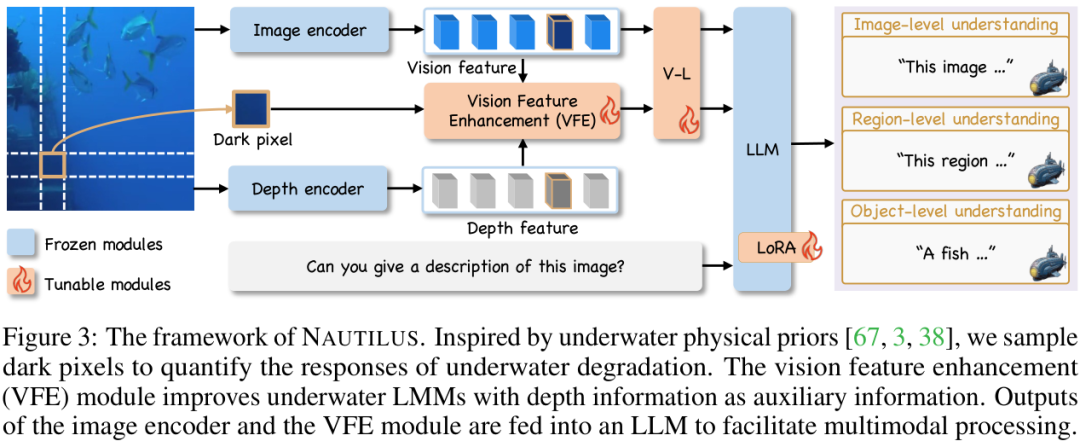
这个VFE模块是一个即插即用的组件,它的设计思想借鉴了水下成像的物理先验知识。简单来说,水下图像的模糊和偏色,可以看作是清晰图像经过某种介质(水)衰减后的结果。VFE模块的目标,就是在特征层面“逆转”这个过程。
它的工作流程是:
-
输入:接收来自图像编码器的视觉特征,同时还利用了图像中的“暗像素”信息和深度信息作为辅助。暗像素可以帮助量化图像的退化程度。
-
处理:模块内部通过一系列操作,对输入的视觉特征进行“修复”和“增强”,以恢复那些被水下环境“吞噬”掉的清晰信息。
-
输出:生成增强后的视觉特征,再送入后续的大语言模型进行多模态的理解和生成。
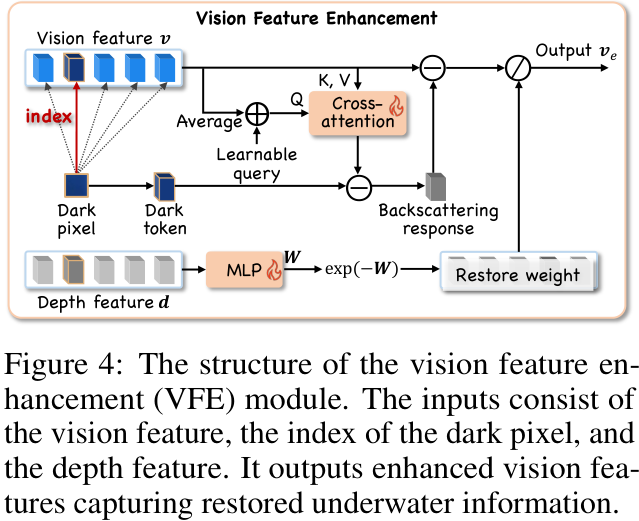
CV君觉得,这种不直接修改图像本身,而是在特征层面进行修复和增强的思路非常巧妙。它避免了传统图像增强算法可能带来的信息丢失或伪影问题,同时作为一个轻量级的即插即用模块,可以很方便地集成到各种主流LMM框架中,通用性很强。
实验效果如何?
是骡子是马,拉出来遛遛。研究者们在新建的NautData测试集和多个公开水下数据集上进行了全面的实验。
多任务全面领先
在NautData测试集上,集成了VFE模块的NAUTILUS(以Qwen2.5-VL为基础)在全部八项任务上,性能相比原始的Qwen2.5-VL都有了一致性的提升,并在大多数任务上超越了包括LLaVA-1.5在内的其他基线模型。
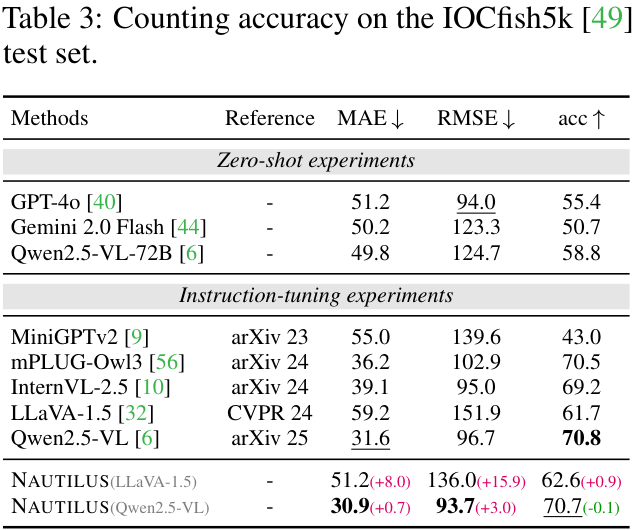
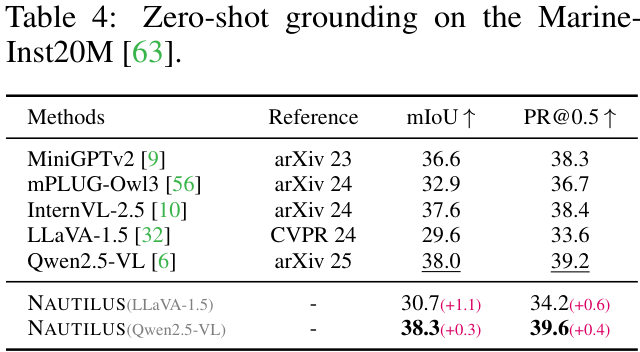
同时,在一些专门的公开数据集上,NAUTILUS也展现了强大的能力。例如,在水下生物计数任务(IOCfish5k数据集)和零样本指代定位任务(Marine-Inst20M数据集)上,NAUTILUS都取得了SOTA或具有竞争力的结果。
消融实验验证VFE模块的有效性
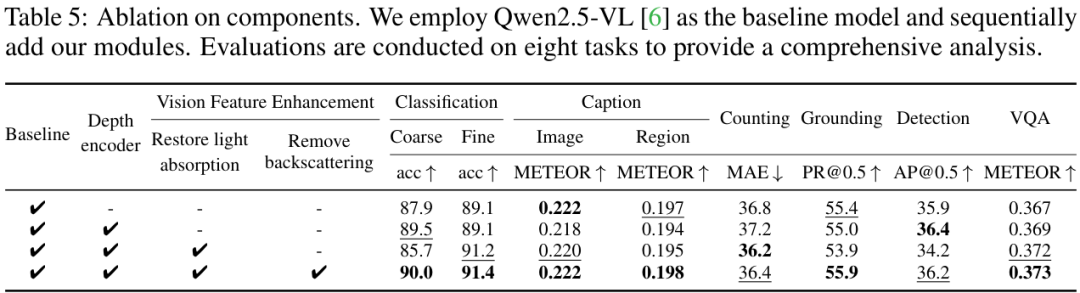
为了证明性能的提升确实来自核心的VFE模块,团队进行了消融研究。实验结果清晰地表明,无论是单独加入VFE模块,还是在使用了NautData进行指令微调后再加入VFE,模型的各项指标都有显著增长。这充分说明了VFE模块的有效性和普适性。
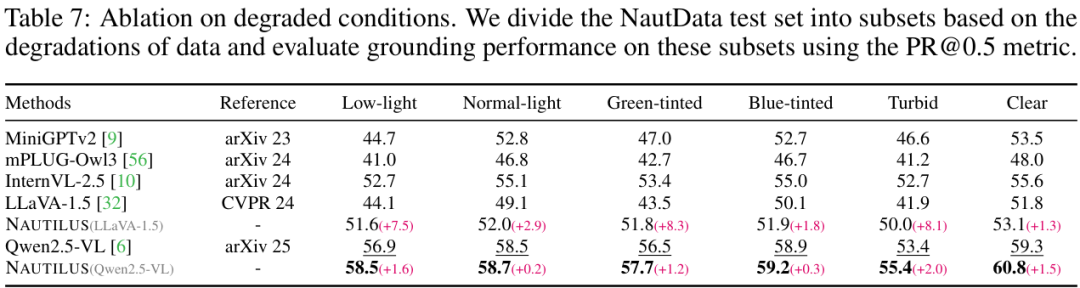
更有趣的是,研究者还将测试数据按退化程度进行了划分。结果发现,在退化更严重的数据上,VFE模块带来的性能提升也更明显。这说明VFE模块确实起到了“对症下药”的作用,精准地解决了水下图像降质这个痛点。
实际效果展示
当然,除了冷冰冰的数字,直观的效果图更能说明问题。从定性结果来看,NAUTILUS能够准确地在复杂的水下场景中进行检测、计数、定位和描述,展现了卓越的多模态指令遵循能力。

总结
总的来说,NAUTILUS这项工作通过“构建大规模专属数据集”和“设计基于物理先验的即插即用增强模块”这两大贡献,为水下场景理解这一充满挑战的领域,提供了一个强大且可扩展的解决方案。
大家觉得这种基于物理先验的增强模块,对其他视觉领域会有怎样的启发?欢迎在评论区聊聊你的看法!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)