【AI论文】少即是多:基于微型网络的递归推理
【研究摘要】本文提出微型递归模型TRM,一种仅含2层网络(700万参数)的轻量级递归推理架构。实验表明,TRM在数独、迷宫及ARC-AGI测试中表现优异:Sudoku-Extreme准确率87.4%,ARC-AGI-1达45%,性能超越参数量大千倍的LLMs(如Gemini2.5Pro)。通过递归更新潜在状态和深度监督策略,TRM实现42层等效推理深度,较HRM模型提升32.4%准确率且训练成本减
摘要:层次推理模型(Hierarchical Reasoning Model, HRM)是一种创新方法,它利用两个以不同频率递归运作的小型神经网络。这种受生物启发的模型在解决数独、迷宫和ARC-AGI等高难度谜题任务时,表现优于大型语言模型(LLMs),且仅通过在小规模数据(约1000个示例)上训练的小型模型(2700万参数)即达成此效果。HRM展示了利用小型网络解决复杂问题的巨大潜力,但其原理尚未完全明晰,且可能并非最优方案。为此,我们提出微型递归模型(Tiny Recursive Model, TRM),这是一种更为简洁的递归推理方法,仅使用一个仅含2层的微型网络,便实现了比HRM显著更高的泛化能力。TRM仅拥有700万参数,在ARC-AGI-1测试集上取得了45%的准确率,在ARC-AGI-2上取得了8%的准确率,其表现优于大多数大型语言模型(如Deepseek R1、o3-mini、Gemini 2.5 Pro),而参数数量却不到这些模型的0.01%。Huggingface链接:Paper page,论文链接:2510.04871
研究背景和目的
研究背景:
随着大型语言模型(LLMs)在自然语言处理任务中的广泛应用,尽管它们在多种任务上展现了强大的能力,但在处理复杂推理任务时仍面临挑战。
例如,在解决数学谜题(如数独)、迷宫路径规划以及抽象推理测试(如ARC-AGI)等任务上,LLMs的表现往往不尽如人意。这些任务要求模型具备高度的逻辑推理能力和问题解决能力,而传统的LLMs由于生成答案的自回归方式,容易因单个错误token导致整个答案失效。为了提高LLMs的可靠性,研究者们提出了多种方法,如Chain-of-Thought(CoT)和Test-Time Compute(TTC),但这些方法仍存在成本高、依赖高质量推理数据以及生成的推理过程可能错误等问题。
与此同时,递归推理作为一种模拟人类思考过程的方法,近年来受到广泛关注。
Hierarchical Reasoning Model (HRM)作为一种新型递归推理模型,通过两个小型神经网络在不同频率下递归推理,在复杂推理任务上取得了显著成绩。然而,HRM的复杂性和对固定点定理的依赖限制了其进一步优化和应用。因此,研究更高效、更简洁的递归推理模型成为迫切需求。
研究目的:
本研究旨在提出一种更简洁、更高效的递归推理模型——Tiny Recursive Model (TRM),以解决复杂推理任务。
具体目标包括:
- 提高推理准确性:通过递归改进预测答案,提高在复杂推理任务上的准确性。
- 减少参数量:使用比HRM更小的网络,实现更高的参数效率。
- 简化模型结构:去除HRM中的复杂数学定理依赖和层次结构,简化模型设计和训练过程。
- 增强泛化能力:通过递归推理和深度监督,提升模型在未见数据上的泛化能力。
研究方法
为了实现上述研究目的,本研究采用了以下研究方法:
1. 模型设计:
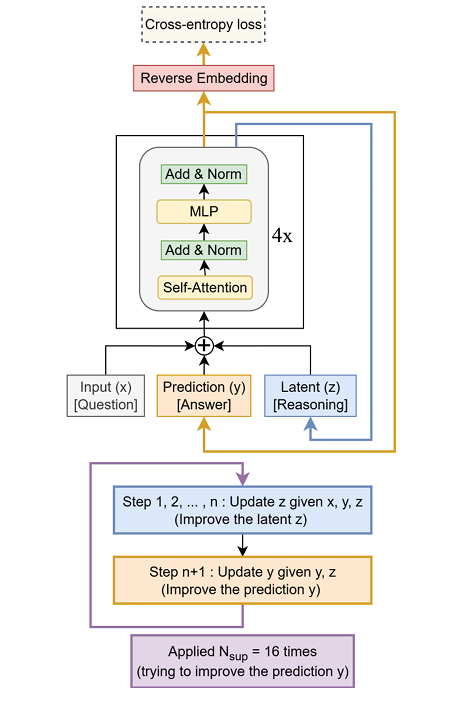
提出了Tiny Recursive Model (TRM),该模型仅包含一个两层的神经网络,通过递归更新潜在推理状态z和预测答案y来逐步改进答案。
TRM的核心思想是通过多次递归更新潜在推理状态z,然后根据当前的z和之前的答案y生成新的答案y',从而逐步逼近正确答案。
2. 递归推理过程:
- 初始答案生成:模型首先生成一个初始的粗略猜测答案y。
- 潜在推理状态更新:通过递归更新潜在推理状态z,模型不断优化其推理逻辑。
- 答案修正:根据当前推理状态z和之前的答案y,模型生成新的答案y'。
- 循环迭代:上述过程最多可重复16次,每次迭代都使模型更接近正确且逻辑严密的解决方案。
3. 训练策略:
- 深度监督:在每个监督步中,模型不仅更新z,还更新答案y,通过多层次的路径传播梯度,显著缓解递归展开造成的梯度消失问题。
- 轻量级自适应计算时间:去除了HRM中的“继续损失”,仅保留是否继续的二元决策,避免了每步两次前向计算,使训练成本减半。
- 指数移动平均(EMA):采用EMA平滑参数轨迹,显著提升泛化能力并稳定收敛。
4. 实验验证:
- 基准测试:在Sudoku-Extreme、Maze-Hard、ARC-AGI等基准测试集上评估模型性能。
- 对比实验:与HRM及其他同质架构模型进行对比,验证TRM的优势。
- 参数调优:通过调整递归次数n和监督步数T等参数,寻找最优模型配置。
研究结果
1. 模型性能提升:
TRM在多个复杂推理任务上显著优于HRM和传统LLMs。
例如,在Sudoku-Extreme任务上,TRM的测试准确率从HRM的55%提升至87.4%;在ARC-AGI-1和ARC-AGI-2上,TRM分别取得了45%和8%的准确率,远超大多数参数量大其千倍的LLMs。
2. 参数效率:
TRM仅用700万参数便实现了超越数十亿参数LLMs的性能。
例如,在Maze-Hard任务上,TRM(7M参数)以85.3%的准确率击败了参数规模大数百倍的DeepSeek-R1和Gemini 2.5 Pro。
3. 递归机制有效性:
通过消融实验验证,递归推理次数n和监督步数T对模型性能有显著影响。
最优配置下(如T=3, n=6),TRM实现了42层等效深度,远超HRM的384层等效深度,同时避免了固定点假设和隐函数定理的依赖。
4. 泛化能力增强:
在数据量极小的场景下(如Sudoku-Extreme仅1000训练样本),TRM通过深度监督和递归推理显著提升了泛化能力,避免了过拟合。
例如,在Sudoku-Extreme上,TRM的测试准确率比HRM高32.4%。
研究局限
尽管TRM在复杂推理任务上展现了显著优势,但本研究仍存在以下局限:
1. 数据依赖性:
TRM的性能高度依赖训练数据的质量和数量。
在小样本场景下,尽管TRM通过深度监督和递归推理提升了泛化能力,但在极端数据稀缺时,模型性能仍可能受限。
2. 任务特异性:
TRM在特定任务(如数独、迷宫)上表现优异,但在其他类型任务(如长文本生成、跨模态理解)上的有效性尚未充分验证。
未来研究需探索TRM在更广泛任务上的适用性。
3. 模型解释性:
尽管TRM通过递归推理提升了性能,但其内部推理过程仍缺乏透明性。
未来研究需进一步探索如何解释TRM的推理过程,提高模型的可解释性。
未来研究方向
针对上述局限,未来研究可从以下几个方面展开:
1. 更大规模模型的实验验证:
在未来研究中,进一步扩大模型规模,验证TRM在更大规模模型下的性能和效率优势。这将有助于推动TRM在实际应用中的广泛部署。
2. 更复杂任务场景的探索:
将TRM应用于更复杂的推理任务,如多步骤数学问题求解、自然语言推理等,验证其在真实场景中的有效性和实用性。通过与实际应用需求的紧密结合,推动TRM技术的不断发展和完善。
3. 跨模态混合架构研究:
随着多模态学习的兴起,未来研究需探索TRM在处理视频、音频等多模态数据时的应用。
通过结合不同模态的特定优势,构建更强大的多模态推理模型。
4. 针对不可见攻击的防御机制:
考虑到大型语言模型面临的安全挑战,未来研究需开发针对不可见攻击(如利用Unicode变体选择符的攻击)的防御机制。
通过结合模型内部表示分析和输出过滤等技术,提高TRM的安全性和鲁棒性。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)