

Transformer模型详解(图解最完整版)
转自:知乎初识CV
建议大家看一下李宏毅老师讲解的Transformer,非常简单易懂(个人觉得史上最强transformer讲解)
前言
Transformer由论文《Attention is All You Need》提出,现在是谷歌云TPU推荐的参考模型。论文相关的Tensorflow的代码可以从GitHub获取,其作为Tensor2Tensor包的一部分。哈佛的NLP团队也实现了一个基于PyTorch的版本,并注释该论文。
在本文中,我们将试图把模型简化一点,并逐一介绍里面的核心概念,希望让普通读者也能轻易理解。
Attention is All You Need:Attention Is All You Need
1.Transformer 整体结构
首先介绍 Transformer 的整体结构,下图是 Transformer 用于中英文翻译的整体结构:
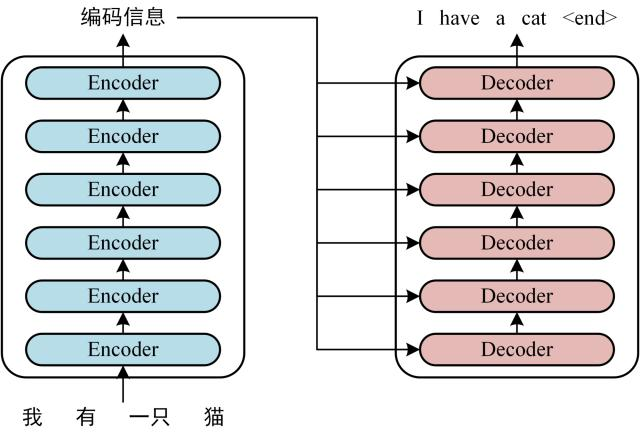
Transformer 的整体结构,左图Encoder和右图Decoder
可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
第一步: 获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
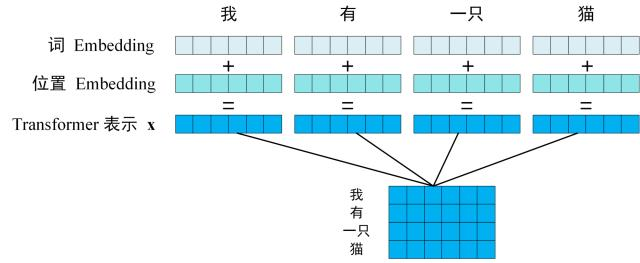
Transformer 的输入表示
第二步: 将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵C,如下图。单词向量矩阵用\(X_{n\times d}\)表示, n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。
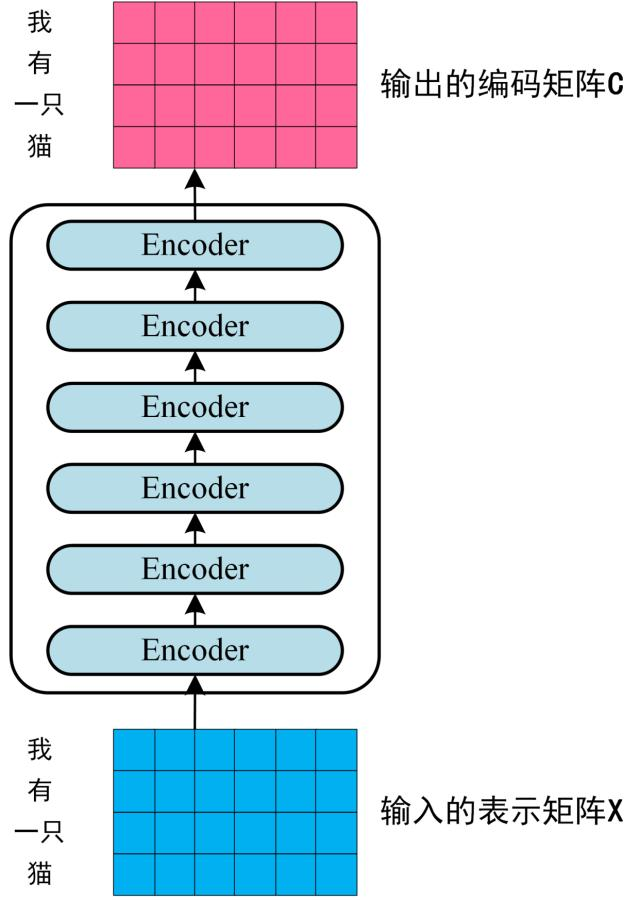
Transformer Encoder 编码句子信息
第三步: 将 Encoder 输出的编码信息矩阵C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
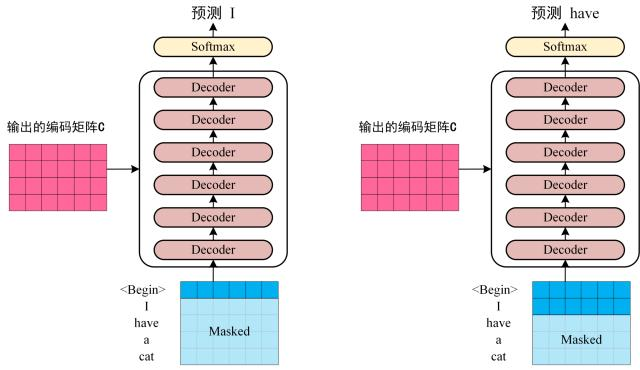
Transofrmer Decoder 预测




 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)