论文阅读——NLP参数高效迁移学习:Adapter方法的深度解析
本文系统解析了NLP参数高效迁移学习中的Adapter方法。该方法通过在Transformer层中插入少量可训练参数(仅占原模型3.6%),实现了接近全微调的性能(99.5%)。关键创新包括:1)瓶颈架构设计,将高维特征压缩到低维空间;2)近恒等初始化策略,确保训练稳定性;3)模块化插入方式,在注意力层和前馈层后双重集成。实验表明,Adapter在GLUE等任务上显著优于传统微调方法,参数效率提升
NLP参数高效迁移学习:Adapter方法的深度解析
Houlsby N, Giurgiu A, Jastrzebski S, et al. Parameter-efficient transfer learning for NLP[C]//International conference on machine learning. PMLR, 2019: 2790-2799.
第一章 引言与研究背景
近年来,预训练模型的迁移学习已成为自然语言处理领域的主导范式。BERT等大规模Transformer模型通过在大规模语料上进行无监督预训练,然后在下游任务上进行微调,取得了前所未有的性能突破。然而,这种方法面临一个根本性挑战:在线学习场景中,当任务以流的形式不断到达时,为每个新任务训练一个完整的新模型在参数效率上是不可接受的。
考虑一个具有参数 w∈Rnw \in \mathbb{R}^nw∈Rn 的神经网络函数 ϕw:X→Y\phi_w: \mathcal{X} \rightarrow \mathcal{Y}ϕw:X→Y。传统的特征提取方法通过组合预训练函数与新函数 χv\chi_vχv 来实现迁移学习,得到复合函数 χv(ϕw(x))\chi_v(\phi_w(x))χv(ϕw(x)),其中只有新参数 vvv 被训练。全参数微调则创建参数 w′w'w′ 的副本并对其进行调整,这意味着对于 KKK 个任务,需要 K×∣w∣K \times |w|K×∣w∣ 的参数存储。
第二章 Adapter理论框架
2.1 数学形式化
Adapter方法的核心创新在于引入了一种新的参数化形式。定义新函数 ψw,v:X→Y\psi_{w,v}: \mathcal{X} \rightarrow \mathcal{Y}ψw,v:X→Y,其中原始参数 www 从预训练模型复制并冻结,新参数 vvv 被初始化为 v0v_0v0,使得:
limv→v0∥ψw,v(x)−ϕw(x)∥2=0,∀x∈X\lim_{v \rightarrow v_0} \|\psi_{w,v}(x) - \phi_w(x)\|_2 = 0, \quad \forall x \in \mathcal{X}v→v0lim∥ψw,v(x)−ϕw(x)∥2=0,∀x∈X
这个性质确保了在训练开始时,适配后的网络行为与原始网络相同,从而保证了训练的稳定性。
2.2 瓶颈架构设计
Adapter模块采用瓶颈架构,对于输入 h∈Rdh \in \mathbb{R}^dh∈Rd,Adapter的前向传播定义为:
Adapter(h)=h+f(h⋅Wdown+bdown)⋅Wup+bup\text{Adapter}(h) = h + f(h \cdot W_{\text{down}} + b_{\text{down}}) \cdot W_{\text{up}} + b_{\text{up}}Adapter(h)=h+f(h⋅Wdown+bdown)⋅Wup+bup
其中 Wdown∈Rd×mW_{\text{down}} \in \mathbb{R}^{d \times m}Wdown∈Rd×m,Wup∈Rm×dW_{\text{up}} \in \mathbb{R}^{m \times d}Wup∈Rm×d,m≪dm \ll dm≪d,fff 是非线性激活函数。
每层的参数量计算为:
Padapter=d⋅m+m+m⋅d+d=2md+m+dP_{\text{adapter}} = d \cdot m + m + m \cdot d + d = 2md + m + dPadapter=d⋅m+m+m⋅d+d=2md+m+d
当 m≪dm \ll dm≪d 时,参数量近似为 2md2md2md,相对于原始层的参数量 d2d^2d2,压缩比为 2md\frac{2m}{d}d2m。
第三章 Transformer集成策略
3.1 插入位置分析
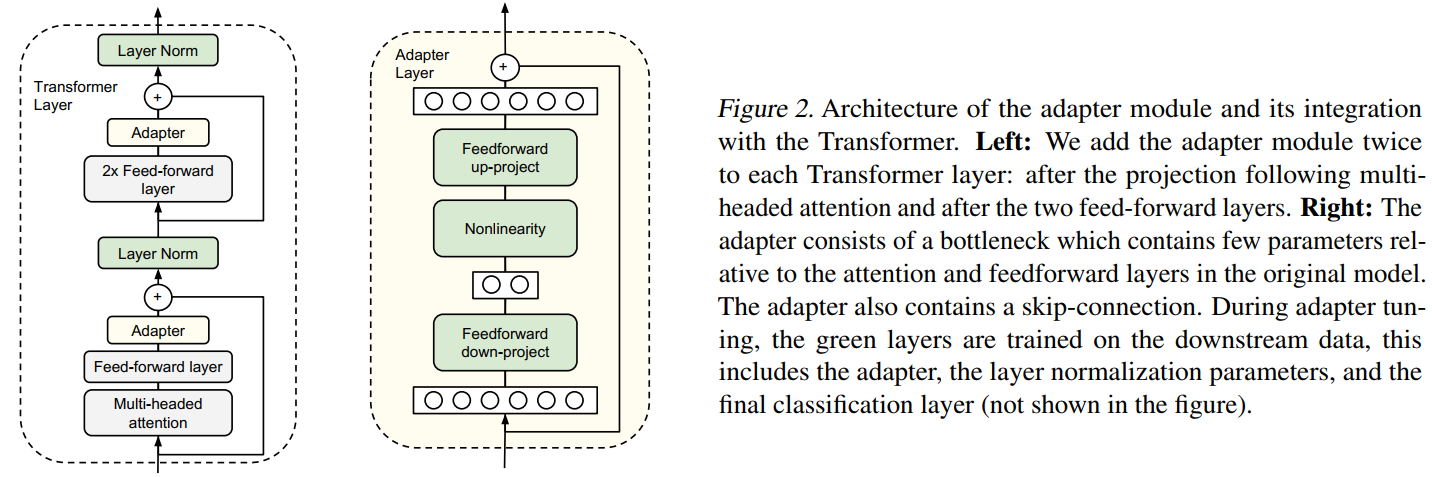
图2描述:左图展示了Adapter模块在Transformer层中的集成位置。Adapter被插入两次:一次在多头注意力投影之后,一次在两个前馈层之后。右图详细展示了Adapter的内部结构,包含向上投影、非线性激活、向下投影和跳跃连接。绿色标记的层(Adapter、层归一化和最终分类层)在下游任务训练时被更新。
在标准Transformer层中,设原始输出为 hsublayerh_{\text{sublayer}}hsublayer,集成Adapter后的计算流程为:
h′=LayerNorm(hinput+Adapter(Sublayer(hinput)))h' = \text{LayerNorm}(h_{\text{input}} + \text{Adapter}(\text{Sublayer}(h_{\text{input}})))h′=LayerNorm(hinput+Adapter(Sublayer(hinput)))
这种设计确保了梯度可以通过两条路径反向传播:通过Adapter的主路径和通过跳跃连接的直接路径。
3.2 初始化策略
为实现近恒等初始化,权重矩阵初始化为:
Wdown∼N(0,σ2I),Wup∼N(0,σ2I)W_{\text{down}} \sim \mathcal{N}(0, \sigma^2 I), \quad W_{\text{up}} \sim \mathcal{N}(0, \sigma^2 I)Wdown∼N(0,σ2I),Wup∼N(0,σ2I)
其中 σ=10−2\sigma = 10^{-2}σ=10−2,并截断到两个标准差。偏置项初始化为零。这确保了:
E[Adapter(h)]≈h+E[f(h⋅Wdown)]⋅E[Wup]≈h\mathbb{E}[\text{Adapter}(h)] \approx h + \mathbb{E}[f(h \cdot W_{\text{down}})] \cdot \mathbb{E}[W_{\text{up}}] \approx hE[Adapter(h)]≈h+E[f(h⋅Wdown)]⋅E[Wup]≈h
第四章 实验设计与结果分析
4.1 GLUE基准测试
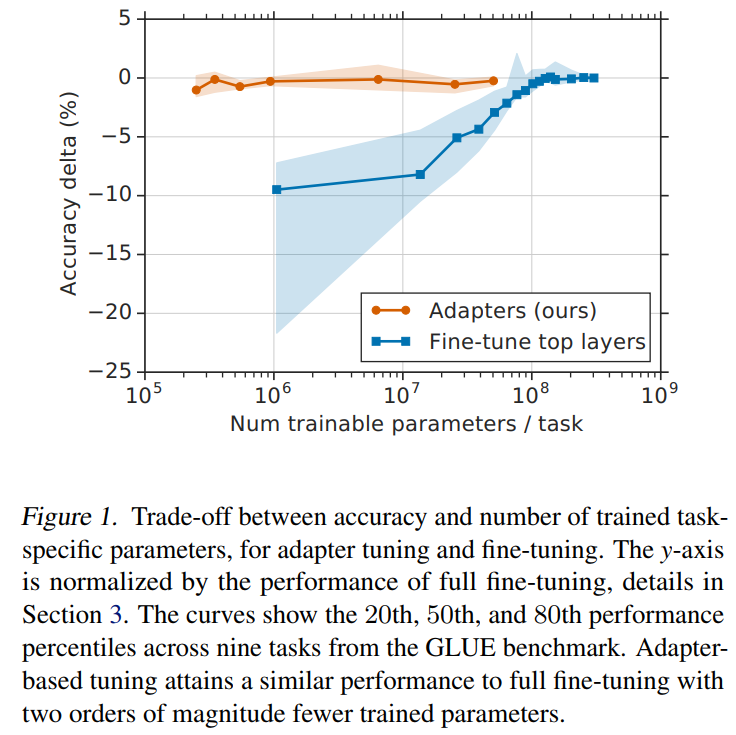
图1描述:该图展示了准确率增量(相对于全微调的百分比)与每个任务训练参数数量之间的权衡关系。橙色线代表不同大小的Adapter,蓝色线代表微调不同数量的顶层。阴影区域表示GLUE基准九个任务的第20、50和80百分位数。Adapter在使用少两个数量级参数的情况下达到了与全微调相当的性能。
实验使用BERTLARGE_{\text{LARGE}}LARGE模型(24层,330M参数)。超参数搜索空间包括:
- 学习率:{3×10−5,3×10−4,3×10−3}\{3 \times 10^{-5}, 3 \times 10^{-4}, 3 \times 10^{-3}\}{3×10−5,3×10−4,3×10−3}
- 训练轮数:{3,20}\{3, 20\}{3,20}
- Adapter大小:{8,64,256}\{8, 64, 256\}{8,64,256}
4.2 消融实验
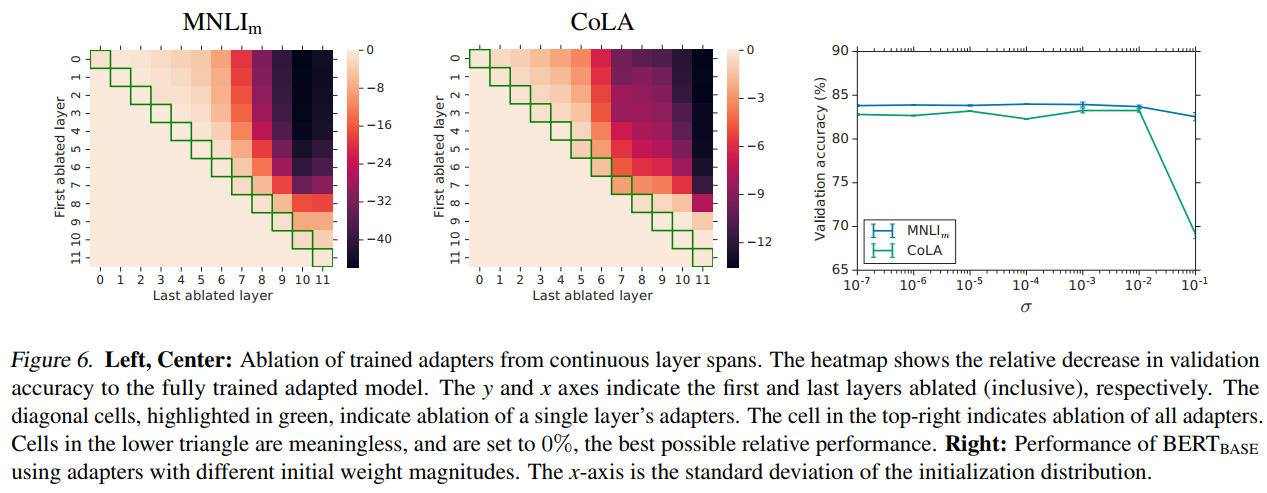
图6描述:展示了从连续层跨度移除训练好的Adapter后的性能影响。左图为MNLIm数据集,中图为CoLA数据集。热图中每个单元格(i,j)(i,j)(i,j)表示移除第iii层到第jjj层(含)的Adapter后验证准确率的相对下降。对角线(绿色高亮)表示仅移除单层。右上角单元格表示移除所有Adapter。右图展示了不同初始化标准差下的性能,x轴为初始化分布的标准差。
消融实验揭示的关键发现:
- 移除单层Adapter的影响较小(Δacc<2%\Delta_{\text{acc}} < 2\%Δacc<2%)
- 低层Adapter(0-4层)的影响明显小于高层
- 移除所有Adapter导致性能降至随机水平
4.3 参数效率分析
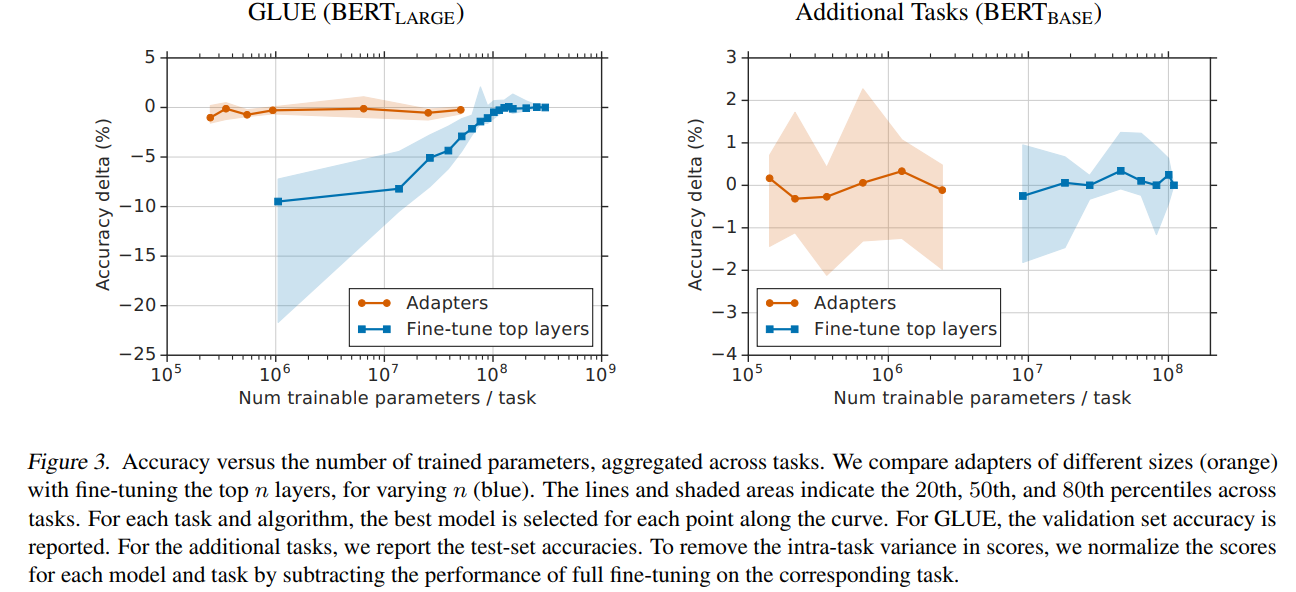
图3描述:展示了聚合跨任务的准确率与训练参数数量的关系。左图为GLUE(BERTLARGE_{\text{LARGE}}LARGE)结果,右图为额外17个分类任务(BERTBASE_{\text{BASE}}BASE)的结果。橙色线表示不同大小的Adapter(2n2^n2n,n=0...9n=0...9n=0...9),蓝色线表示微调顶部kkk层(k=1...12k=1...12k=1...12)。线条和阴影区域表示任务间的第20、50和80百分位数。
关键发现:在GLUE上,Adapter仅用3.6%的参数达到了全微调99.5%的性能(80.0 vs 80.4)。在额外的17个分类任务上,Adapter用1.14%的参数达到了99.5%的性能(73.3 vs 73.7)。
第五章 不同任务的泛化能力
5.1 SQuAD问答任务
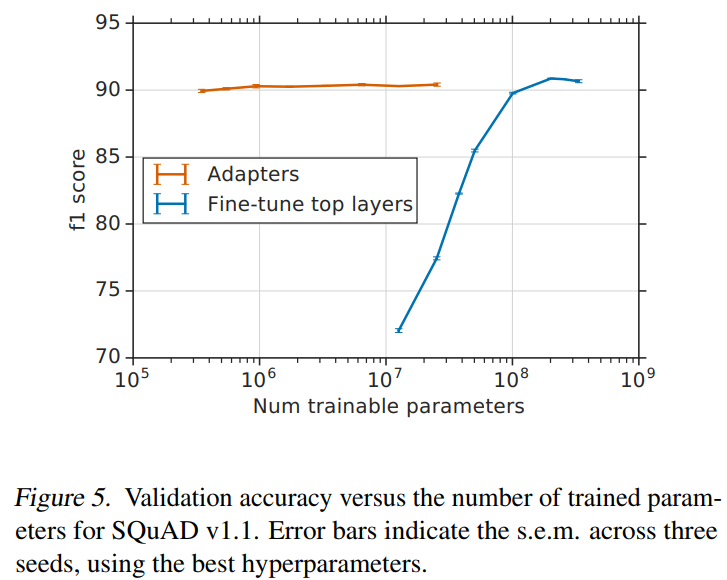
图5描述:SQuAD v1.1验证集上的F1分数与训练参数数量的关系。误差条表示三个随机种子的标准误。图中显示即使是极小的Adapter(大小为2,占0.1%参数)也能达到89.9的F1分数,而64大小的Adapter(2%参数)达到90.4,接近全微调的90.7。
5.2 学习率鲁棒性
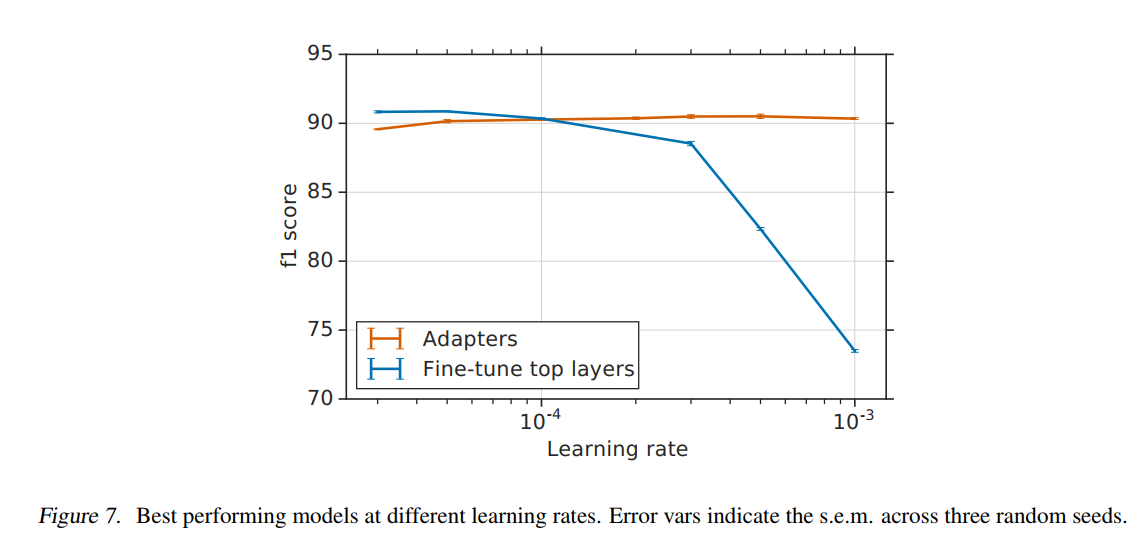
图7描述:不同学习率下的最佳模型性能。实验测试了[2×10−5,10−3][2 \times 10^{-5}, 10^{-3}][2×10−5,10−3]范围内的学习率。Adapter在整个范围内保持稳定性能(橙色线),而顶层微调(蓝色线)在高学习率下性能急剧下降。这表明Adapter方法对超参数选择更加鲁棒。
第六章 与其他方法的详细比较
6.1 层归一化调优
仅调整层归一化参数的方法虽然极其参数高效(BERTBASE_{\text{BASE}}BASE仅需40k参数),但性能显著下降:
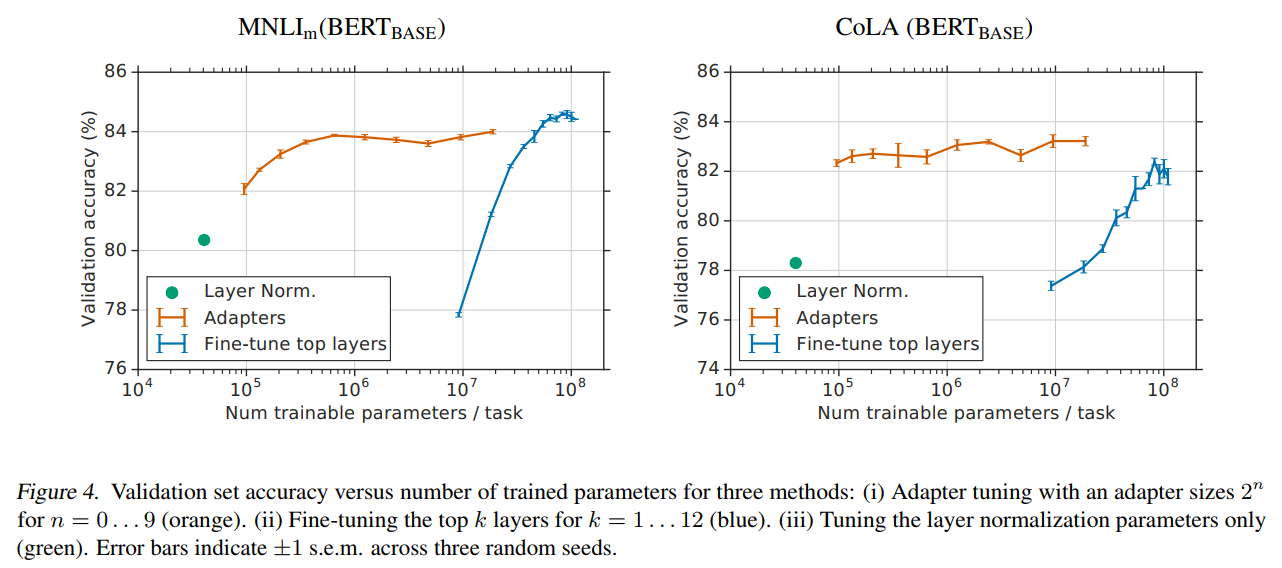
图4描述:MNLIm(左)和CoLA(右)数据集上验证准确率与训练参数数量的关系。绿色点表示仅调整层归一化参数,橙色线表示不同大小的Adapter,蓝色线表示微调顶部kkk层。层归一化方法在两个数据集上分别下降约4%和3.5%的准确率。
6.2 变量微调(Variable Fine-tuning)
实验比较了微调顶部nnn层的策略,其中n∈{1,2,3,5,7,9,11,12}n \in \{1,2,3,5,7,9,11,12\}n∈{1,2,3,5,7,9,11,12}。结果表明,当参数数量相当时,Adapter显著优于部分层微调。例如,在MNLIm上:
- 微调顶层(9M参数):77.8% ±\pm± 0.1%
- Adapter-64(2M参数):83.7% ±\pm± 0.1%
- 全微调(110M参数):84.4% ±\pm± 0.02%
附录A:理论推导
A.1 近恒等初始化的数学证明
给定Adapter函数:
A(h)=h+g(h)A(h) = h + g(h)A(h)=h+g(h)
其中 g(h)=ReLU(hWdown+bdown)Wup+bupg(h) = \text{ReLU}(hW_{\text{down}} + b_{\text{down}})W_{\text{up}} + b_{\text{up}}g(h)=ReLU(hWdown+bdown)Wup+bup
当权重初始化为小值时,我们可以通过泰勒展开分析:
g(h)=ReLU(hWdown)Wup+O(∥W∥2)g(h) = \text{ReLU}(hW_{\text{down}})W_{\text{up}} + \mathcal{O}(\|W\|^2)g(h)=ReLU(hWdown)Wup+O(∥W∥2)
对于ReLU激活函数,当输入接近零时:
E[ReLU(x)]=12E[∣x∣]≈σ2π∥h∥\mathbb{E}[\text{ReLU}(x)] = \frac{1}{2}\mathbb{E}[|x|] \approx \frac{\sigma}{\sqrt{2\pi}}\|h\|E[ReLU(x)]=21E[∣x∣]≈2πσ∥h∥
因此:
E[g(h)]=E[ReLU(hWdown)]⋅E[Wup]=O(σ2)\mathbb{E}[g(h)] = \mathbb{E}[\text{ReLU}(hW_{\text{down}})] \cdot \mathbb{E}[W_{\text{up}}] = \mathcal{O}(\sigma^2)E[g(h)]=E[ReLU(hWdown)]⋅E[Wup]=O(σ2)
当 σ=10−2\sigma = 10^{-2}σ=10−2 时,E[A(h)]≈h+O(10−4)≈h\mathbb{E}[A(h)] \approx h + \mathcal{O}(10^{-4}) \approx hE[A(h)]≈h+O(10−4)≈h
A.2 梯度流分析
考虑损失函数 L\mathcal{L}L 对Adapter输入 hhh 的梯度:
∂L∂h=∂L∂A(h)⋅∂A(h)∂h\frac{\partial \mathcal{L}}{\partial h} = \frac{\partial \mathcal{L}}{\partial A(h)} \cdot \frac{\partial A(h)}{\partial h}∂h∂L=∂A(h)∂L⋅∂h∂A(h)
其中:
∂A(h)∂h=I+∂g(h)∂h\frac{\partial A(h)}{\partial h} = I + \frac{\partial g(h)}{\partial h}∂h∂A(h)=I+∂h∂g(h)
由于跳跃连接的存在,即使 ∂g(h)∂h≈0\frac{\partial g(h)}{\partial h} \approx 0∂h∂g(h)≈0(在初始化时),梯度仍然可以通过恒等项 III 传播,避免了梯度消失问题。
A.3 参数效率的理论界限
设原始网络有 LLL 层,每层维度为 ddd。全微调的参数量为 O(Ld2)\mathcal{O}(Ld^2)O(Ld2)。使用瓶颈维度 mmm 的Adapter,参数量为:
Ptotal=2L×(2md+m+d)≈4LmdP_{\text{total}} = 2L \times (2md + m + d) \approx 4LmdPtotal=2L×(2md+m+d)≈4Lmd
压缩比为:
ρ=PtotalPoriginal=4LmdLd2=4md\rho = \frac{P_{\text{total}}}{P_{\text{original}}} = \frac{4Lmd}{Ld^2} = \frac{4m}{d}ρ=PoriginalPtotal=Ld24Lmd=d4m
对于BERTLARGE_{\text{LARGE}}LARGE(d=1024d=1024d=1024),使用 m=64m=64m=64 时,ρ≈0.25\rho \approx 0.25ρ≈0.25,但由于只有Adapter和层归一化被训练,实际可训练参数比例约为3.6%。
A.4 多任务场景的存储复杂度
对于 KKK 个任务:
- 全微调:O(KLd2)\mathcal{O}(KLd^2)O(KLd2)
- Adapter:O(Ld2+4KLmd)\mathcal{O}(Ld^2 + 4KLmd)O(Ld2+4KLmd)
当 K≫d4mK \gg \frac{d}{4m}K≫4md 时,Adapter方法的优势变得显著。例如,当 d=1024d=1024d=1024,m=64m=64m=64 时,K>4K > 4K>4 即可实现存储节省。
结论
这项研究通过引入Adapter模块,为大规模预训练模型的参数高效迁移学习提供了一个优雅而有效的解决方案。通过严格的数学分析和广泛的实验验证,论文证明了Adapter方法在保持接近全参数微调性能的同时,将参数需求降低了两个数量级。这种方法不仅在理论上具有坚实的基础,在实践中也展现了强大的泛化能力和鲁棒性,为构建可扩展的NLP系统开辟了新的方向。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)