网络模型优化方法-Adam(自适应矩估计)
摘要:Adam(自适应矩估计)是深度学习中主流的优化算法,结合动量法和RMSProp的优势,通过动态调整学习率提升训练效率。它维护一阶/二阶矩估计,自动适应不同参数特性,具有收敛快、稳定性强等优点,广泛应用于CV、NLP等领域。尽管存在超参数敏感等局限,Adam仍是复杂模型训练的优选方案,其通用性使其成为深度学习发展的重要推动力。(149字)
Adam(Adaptive Moment Estimation,自适应矩估计)是深度学习中广泛应用的优化算法,由 Diederik P. Kingma 和 Jimmy Lei Ba 于 2014 年提出。它结合了动量法(Momentum)和 RMSProp 算法的优点,通过自适应调整每个参数的学习率,显著提升模型训练的收敛速度和稳定性。
🔍 一、核心思想与工作原理
Adam 的核心是通过维护两个关键统计量动态调整学习率:
-
一阶矩估计(动量):计算梯度的指数加权平均(类似 Momentum),保留历史梯度方向,加速收敛并抑制震荡。

-
二阶矩估计(自适应学习率):计算梯度平方的指数加权平均(类似 RMSProp),根据梯度幅度调整步长。梯度大的参数减小学习率,梯度小的参数增大学习率。
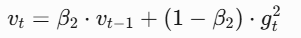
-
偏差修正:由于初始时刻 mt 和 vt 接近 0,需修正以提升稳定性:

-
参数更新:结合修正后的矩估计调整参数:
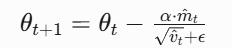
- 超参数说明:α(学习率,默认 0.001)、β1(动量衰减率,默认 0.9)、β2(梯度平方衰减率,默认 0.999)、ϵ(防除零常数,默认
 ).
).
- 超参数说明:α(学习率,默认 0.001)、β1(动量衰减率,默认 0.9)、β2(梯度平方衰减率,默认 0.999)、ϵ(防除零常数,默认
⚖️ 二、优势与局限
优势:
- 自适应学习率:无需手动调整学习率,自动适应不同参数的梯度特性。
- 高效稳定:结合动量与自适应学习率,收敛速度快且不易陷入局部最优或鞍点。
- 鲁棒性强:尤其适合处理稀疏梯度(如 NLP 任务)和非平稳目标函数。
- 低内存需求:相比 Adagrad 等算法,内存占用更小。
局限:
- 超参数敏感:默认参数虽通用,但在特定任务(如生成模型)仍需调优。
- 内存占用:需存储一阶/二阶矩估计,内存略高于 SGD。
- 泛化争议:部分研究指出其可能比 SGD 泛化能力略弱,需结合学习率调度器。
🆚 三、与其他优化器的对比
| 特性 | SGD | RMSprop | Adam |
|---|---|---|---|
| 自适应学习率 | ❌ | ✅ | ✅ |
| 动量机制 | ❌(需手动添加) | ❌ | ✅(内置) |
| 收敛速度 | 慢 | 中等 | 快 |
| 稳定性 | 易震荡 | 较稳定 | 稳定 |
| 适用场景 | 小数据集、简单模型 | RNN、非平稳目标 | 大规模复杂模型 |
例如,在拟合非线性函数时,Adam 的收敛速度可比 SGD 快 3-5 倍,且损失曲线更平滑。
💻 四、实际应用场景
- 计算机视觉(CV):ResNet、CNN 等模型的默认优化器。
- 自然语言处理(NLP):处理词嵌入等稀疏梯度任务时效果显著。
- 强化学习:适应非平稳目标函数,如策略梯度方法。
- 生成模型:VAE、扩散模型中广泛采用。
代码示例(PyTorch):
import torch.optim as optim
model = ... # 定义神经网络
optimizer = optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999))💎 五、总结
Adam 通过动态融合梯度历史(动量)和局部变化(自适应学习率),成为深度学习领域的“通用优化器”。其设计平衡了速度与稳定性,尤其适合大规模数据和复杂模型。尽管存在少量局限,其影响力仍不可替代——2025 年,Adam 论文因推动深度学习发展获 ICLR 时间检验奖。在实际应用中,建议优先尝试 Adam,并在复杂任务中结合学习率调度器以进一步提升性能。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)