World4Drive:端到端自动驾驶中意图-觉察物理潜世界模型
25年7月来自中科院自动化所、理想汽车、鹏程实验室、新加坡国立大学和清华大学的论文“World4Drive: End-to-End Autonomous Driving via Intention-aware Physical Latent World Model”。端到端自动驾驶直接从原始传感器数据生成规划轨迹,但它通常依赖于昂贵的感知监督来提取场景信息。一个关键的研究挑战是:构建一个信息丰富的
25年7月来自中科院自动化所、理想汽车、鹏程实验室、新加坡国立大学和清华大学的论文“World4Drive: End-to-End Autonomous Driving via Intention-aware Physical Latent World Model”。
端到端自动驾驶直接从原始传感器数据生成规划轨迹,但它通常依赖于昂贵的感知监督来提取场景信息。一个关键的研究挑战是:构建一个信息丰富的驾驶世界模型,以便通过自监督学习实现无感知注释的端到端规划。本文提出 World4Drive,这是一个端到端自动驾驶框架,它采用视觉基础模型构建潜世界模型,用于生成和评估多模态规划轨迹。具体来说,World4Drive 首先提取场景特征,包括驾驶意图和世界潜表示,这些特征由视觉基础模型提供的空间语义先验所丰富。然后,它根据当前场景特征和驾驶意图生成多模态规划轨迹,并在潜空间内预测多个意图驱动的未来状态。最后,它引入一个世界模型选择器模块来评估和选择最佳轨迹。在实际未来观测值与从潜空间重建的预测观测值之间进行自监督对齐,实现无需感知注释的端到端规划。World4Drive 在开环 nuScenes 和闭环 NavSim 基准测试中均实现无需手动感知注释的最佳性能,L2 误差相对降低了 18.1%,碰撞率降低了 46.7%,训练收敛速度提高了 3.75 倍。
World4Drive 的整体流程如图所示。World4Drive 包含两个关键模块:1)驾驶世界编码,从 RGB 图像和轨迹词汇中提取驾驶意图和物理世界的潜表征;2)意图-觉察世界模型,根据多模态驾驶意图预测未来世界的潜表征,并通过世界模型选择器对多模态规划轨迹进行评分。这两个关键模块紧密耦合,使自动驾驶汽车能够想象各种意图下的未来世界,同时实现基于视觉的端到端规划,而无需感知注释。
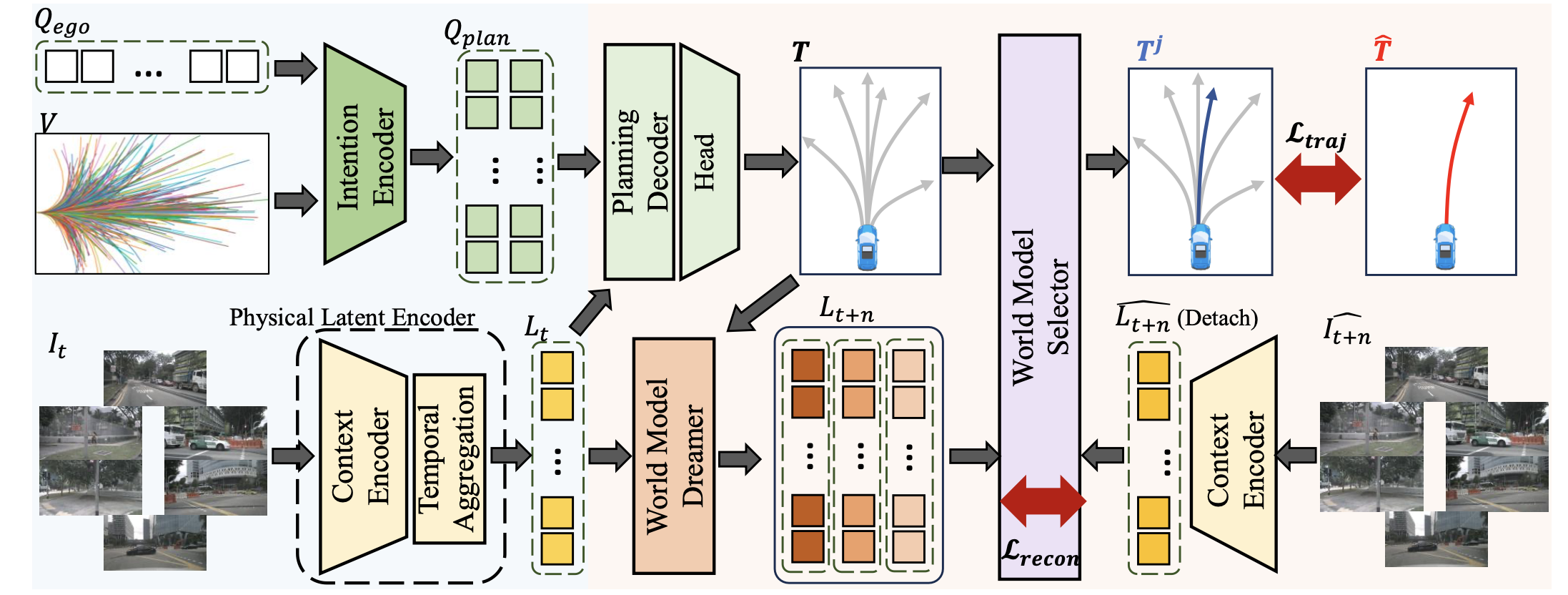
驾驶世界编码
在驾驶世界编码模块中,引入一个意图编码器,以词汇表为输入提取驾驶意图;以及一个物理潜编码器,利用视觉语言模型和度量深度估计模型提取能够觉察空间、语义和时间上下文的世界潜表示。
意图编码器
给定一个随机初始化的自我查询 Q_ego 和一个轨迹词汇表 V 输入 [3],首先采用 K -均值聚类算法对 V 的端点进行聚类,得到意图点 P_I。其中,N 表示轨迹词汇表中的轨迹数量,3 表示三种指令类型(例如,左转、右转、直行),K 表示每种指令类型的意图数量,S 表示每条轨迹中的路径点数量。然后,采用正弦位置编码得到意图查询 Q_I。最后,用自注意层来获得意图-觉察的多模态规划查询 Q_plan。
物理世界潜编码
引入物理世界潜编码模块,提取具有对三维物理世界整体理解(即空间和语义感知能力)的世界潜表征。该模块包含一个上下文编码器(详见下图),用于整合空间和语义先验,以及一个时间聚合模块,用于增强时间上下文。
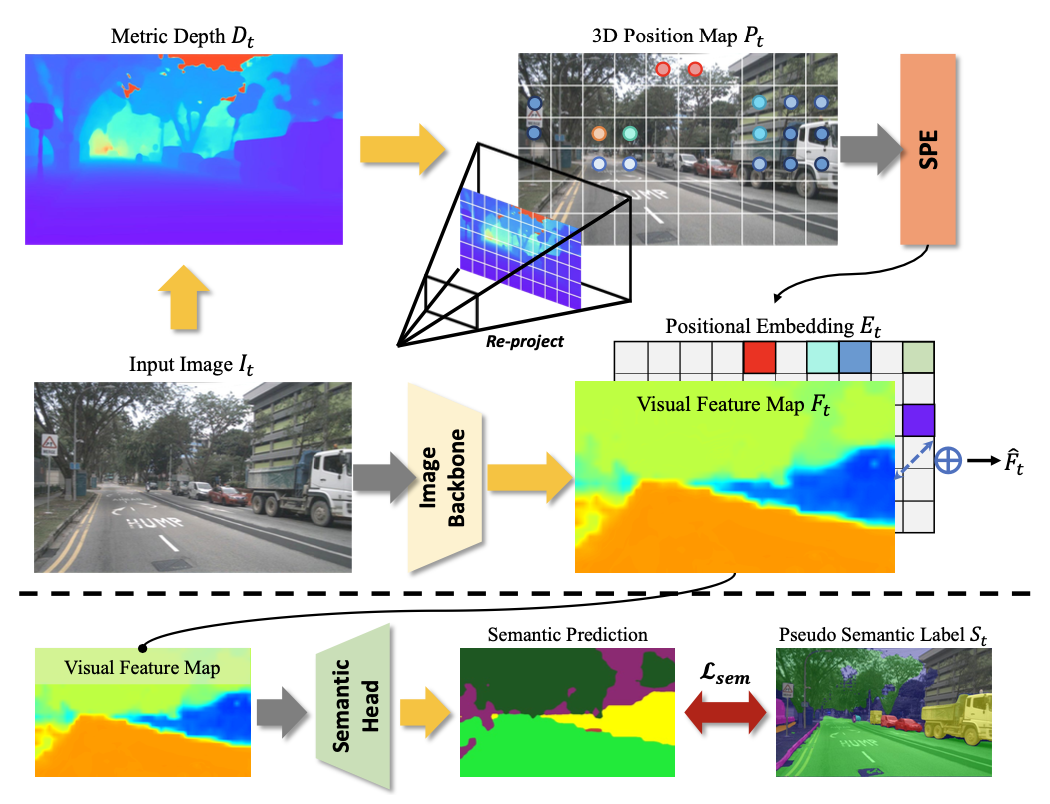
上下文编码器。给定时间步长 t 的一帧多视角图像 I_t 作为输入,首先使用图像主干提取相应的图像特征 F_t,D 表示特征维度,M 表示摄像机视角数量。先前的研究 LAW [18]直接提取摄像机特征作为世界潜表征,缺乏对驾驶场景的空间和语义理解。为了解决这个问题,引入空间语义先验,并采用开放词汇语义监督和三维几何感知位置编码。
语义理解。用视觉语言模型 Grouded-SAM [31] 生成伪语义标签。给定感兴趣目标的提示,通过 Grouded-SAM 模型获取二维边框和相应的语义掩码 S_t。只保留置信度高的标签,以减少错误标记。最后,利用交叉熵损失 Lsem 来增强对潜表示的语义理解。
3D 空间编码。3D 空间编码旨在为模型提供物理世界中的精确位置信息。先前的研究 PETR [25] 利用后向投影方法生成 3D 网格,为每个像素提供不同的 3D 位置编码。受此概念的启发,为每个像素提供尺度-觉察的深度来表示 3D 空间,从而为端到端规划提供精确的空间理解。具体来说,采用度量深度模型 [11, 43] 来估计多视角深度图 D_t。与 PETR 不同,本文采用前向投影方法,通过深度图和相机本征矩阵获取每个像素 (u, v) 在自身坐标系 p = {x, y, z} 中的三维位置。由此,可以生成三维位置图 P_t。随后,用正弦位置编码对这些三维位置进行编码,并通过可学习的多层感知器 (MLP) 获得相应的位置嵌入 E_t。最后,通过将位置嵌入 E_t 添加到图像特征 F_t,获得具有语义-空间-觉察的视觉特征 Fˆ_t。
时间聚合。与先前 [18] 使用随机初始化查询来获取潜表示的研究不同,用时间聚合模块来获取富含时间上下文的潜表示。具体来说,保留先前时间戳 t − 1 处的视觉特征 Fˆ_t−1。为了增强世界潜表征中的时间信息,通过交叉注意机制将历史信息聚合到当前视觉特征中,以获得世界潜表征 L_t。该提出的物理世界潜编码器利用空间、语义和时间信息丰富了世界潜表征,从而提供对动态驾驶环境的整体理解,这对于构想未来世界至关重要。
用意图-觉察世界模型进行规划
意图-觉察世界模型,根据多模态驾驶意图预测未来世界的潜表征,并通过世界模型选择器对多模态规划轨迹进行评分。
意图-觉察世界模型 Dreamer
动作编码。给定意图-觉察的多模态规划查询 Q_plan,首先使用交叉注意层将场景上下文聚合到 Q_plan 中。然后,用多层感知器 (MLP) 层获取多模态轨迹 T = {T1, …, TK}。最后,用动作编码器(MLP 层)获取意图-觉察的动作 token A,其中 K 是意图的数量。
意图-觉察世界模型预测。目标是预测每个驾驶意图对应的未来动作跟从的世界潜变量 L_t+n = {L1_t+n, …, LK_t+n},其中 n 是时间戳间隔。沿维度通道连接动作 token A 和世界潜变量 L。与之前的研究不同,随机初始化一个可学习的查询 Q_future,并采用多层交叉注意作为预测器。默认情况下,设置 n = 3。
世界模型选择器
提出一个世界模型选择器模块,该模块通过潜世界模型评估 K 种不同意图下的轨迹,并从中选择合理的轨迹。其详细架构如图所示。
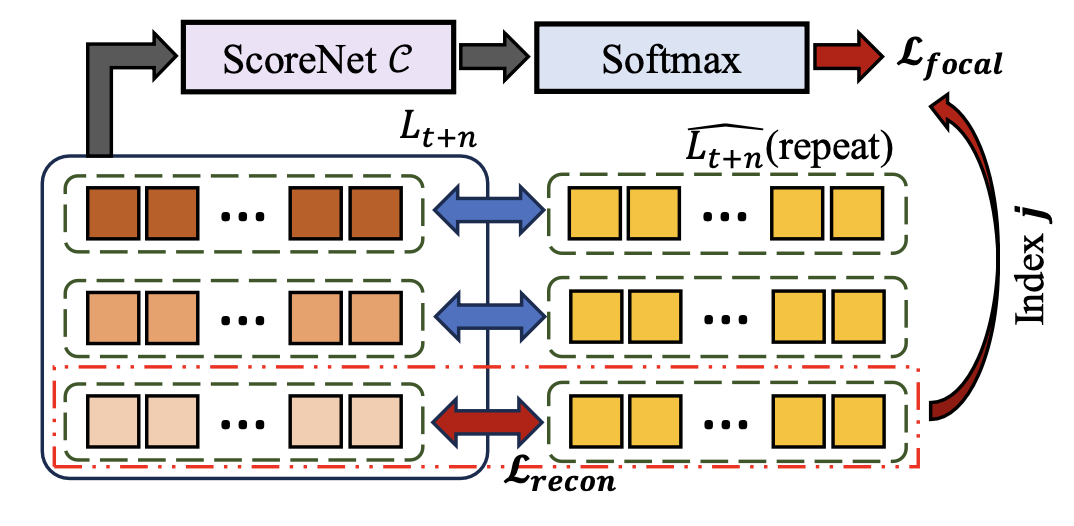
具体来说,给定预测的意图-觉察未来潜向量 L_t+n 和实际未来潜向量 Lˆ_t+n,计算每个模态的预测潜表示之间的特征距离。选择距离最小的模态作为最终选定模态(假设该模态的索引为 j),相应的潜距离作为重构损失 L_recon 进行优化,并选择相应的轨迹 Tj 作为最终规划轨迹。同时,使用分类网络 ScoreNet C 来预测 K 个模态对应的分数 S = {S1,…SK}。利用得分 S 与所选模态索引 j 之间的焦点损失来优化世界模型得分网络。
值得注意的是:1)在推理过程中,直接选择得分最高世界模型对应的轨迹作为最终轨迹;2)用 MSE 损失来计算潜距离。
训练损失
沿袭前人的研究,应用 L1 损失 L_traj,利用专家轨迹 Tˆ 来指导最终规划轨迹 Tj。World4Drive 是端到端可训练的。因此,端到端训练的最终损失是这些损失项的组合:语义、重建、分类和轨迹等。
基准
开环基准。nuScenes [2] 基准测试是为现实世界 nuScenes 数据集开发的开环评估框架。nuScenes 数据集包含在不同环境下捕获的 1000 个驾驶视频。与以前的方法 [13、16] 一致,用位移误差 (L2) 和碰撞率 (CR) 作为预测轨迹的评估指标,这些轨迹在 3 秒的范围内以 2Hz 的频率采样。
闭环 NavSim 基准测试。NavSim [14] 基准测试基于 OpenScene [5] 数据集构建,包含 1192 个训练场景和 136 个测试场景,总共超过 100,000 个关键帧。与官方提供的基线保持一致,用 LQR 控制器对预测轨迹(在 4 秒的范围内以 2Hz 的频率采样)进行插值。模型性能通过闭环 PDM 得分 (PDMS) 进行评估,该得分基于五个关键因素计算得出:无过错碰撞 (NC)、可驾驶区域合规性 (DAC)、碰撞时间 (TTC)、舒适度 (Comf.) 和自我进度 (EP)。
实现细节
nuScenes 基准测试。遵循 VAD-Tiny [16] 配置,用 ResNet-50 [8] 作为图像主干,处理 6 张分辨率为 360 × 640 的环视图像。驾驶指令与先前研究 [13] 一致,包含三种类型:左转、右转和直行。对于每个指令,预测 6 条规划轨迹,并选择与世界模型对应的得分最高的一条作为最终规划轨迹。在 8 块 NVIDIA 3090 GPU 上对模型进行 12 个 epoch 的训练,总批次大小为 8,初始学习率为 5e-5。
NavSim 基准测试。与 NavSim 基准测试一致,闭环模型以拼接前方、左前和右前摄像头视图形成的级联图像作为输入,然后将其调整为 256 × 1024。用 ResNet-34 [8] 提取图像特征。在 8 块 NVIDIA 3090 GPU 上对模型进行了 60 个 epoch 的训练,总批次大小为 64。由于 LAW [18] 并非开源,重新实现并在与相同的设置下对其进行评估。对于视觉基础模型,用 Metric3D v2 [11] 中的 giant 模型进行深度估计,并使用 Grounded-SAM [31] 进行语义分割。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)